
Cada vez que abres una conversación nueva con tu IA, vuelves a explicar lo mismo: quién eres, qué hace tu empresa, tu tono, tus casos de estudio. Pagas por procesar información que la IA ya vio.
Ese es el coste invisible del contexto repetido: tokens gastados en redundancia.
El problema escala cuando gestionas múltiples clientes, proyectos o equipos. Cada persona repite el mismo contexto. El gasto se multiplica silenciosamente. Ahorrar tokens con memoria persistente ataca el origen: almacenas contexto una vez y tu IA lo reutiliza automáticamente. No comprimes prompts. Cambias la arquitectura: pagas por contexto nuevo, no por contexto reciclado.
Conclusiones clave
- El contexto repetido es el mayor gasto invisible en tu factura de IA: cada vez que explicas lo mismo, pagas por procesar tokens que tu asistente ya había visto.
- La memoria persistente ataca el problema estructural: almacena contexto una vez y lo reutiliza automáticamente, reduciendo el coste sin comprometer la calidad de las respuestas.
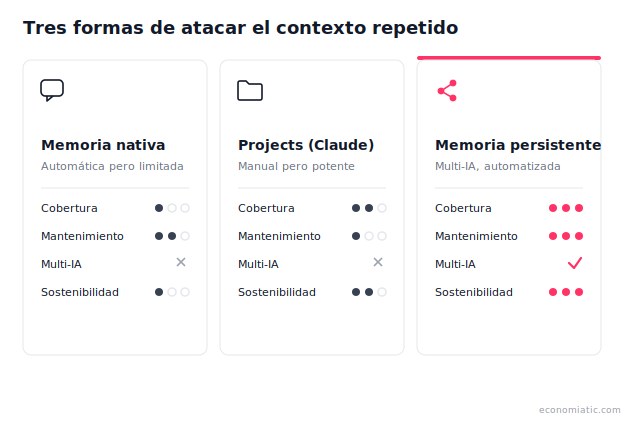
- Tres opciones disponibles con trade-offs distintos: memoria nativa de cada IA (limitada, pero fácil), Projects de Claude (poderosa pero manual), y memoria persistente multi-IA (automatizada, portable).
El contexto repetido es información que tu IA ya procesó pero que vuelves a enviar porque cada sesión es independiente. Esta repetición constante hace que reducir tokens IA sea casi imposible sin cambiar la arquitectura de cómo compartes información con tu asistente.
No hablamos de recordar conversaciones (memoria episódica), sino de hechos estables: quién eres, qué hace tu empresa, preferencias de estilo, casos de estudio, métricas clave.
Un token es aproximadamente una sílaba o palabra corta — 800 tokens equivalen a unas 600 palabras, similar a un email largo. Cada vez que abres una conversación y dices "soy el CEO de una startup SaaS B2B", pagas por procesar esa frase. Si lo repites 50 veces al mes, pagas 50 veces. Anthropic cobra $3 por millón de tokens de entrada en Sonnet 4 y $15 en Opus 41.
La memoria persistente elimina la repetición desde el origen, produciendo un gran ahorro en tokens. En esta guía aprenderás a implementarla paso a paso con tres opciones — desde la gratuita hasta la más avanzada — y verás exactamente cuánto puedes ahorrar.
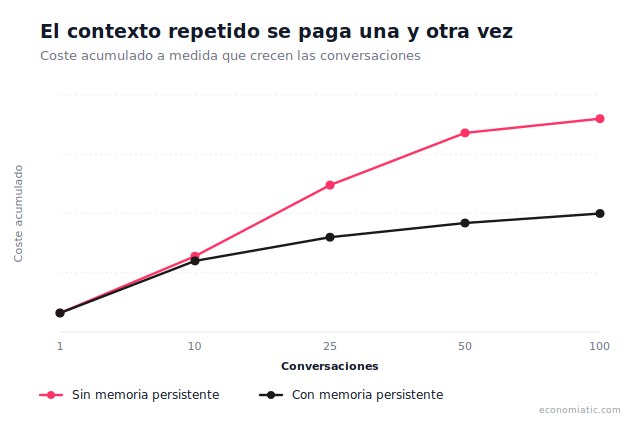
Existen tres maneras de reducir el coste de tokens IA, cada una con trade-offs distintos. Para optimizar tokens en Claude, ChatGPT y otros modelos, necesitas entender qué resuelve cada opción y qué no.
Claude, ChatGPT y otras IAs modernas tienen memoria interna: recuerdan fragmentos de conversaciones previas y los aplican automáticamente en sesiones futuras.
Los Projects son espacios de trabajo persistentes donde puedes definir contexto estático (instrucciones, documentos, guidelines) que Claude lee automáticamente en cada conversación dentro de ese espacio.
Sistemas que centralizan tu contexto en un único lugar y lo sincronizan con todas las IAs que uses. Estos sistemas usan MCP (Model Context Protocol)2, el estándar abierto creado por Anthropic para conectar herramientas externas a modelos de lenguaje
Piensa en MCP como un USB para conexiones de IA: un estándar que permite que cualquier herramienta se conecte a cualquier IA sin hacerlo a medida para cada una.
| Aspecto | Memoria nativa | Projects (Claude) | Memoria persistente |
|---|---|---|---|
| Cobertura | Solo lo mencionado explícitamente | Todo el contexto que definas manualmente | Contexto estructurado + automático |
| Mantenimiento | Automático pero limitado | Manual, requiere edición constante | Automático con actualizaciones propagadas |
| Multi-IA | No (cada IA es un silo) | No (solo Claude) | Sí (Claude + ChatGPT vía MCP) |
| Sostenibilidad a largo plazo | Se degrada si no refuerzas | Sostenible si mantienes el Project | Escala sin fricción adicional |
| Estado actual | Disponible en todas las IAs | Disponible en Claude | Beta abierta |
Cada opción resuelve un problema distinto:
Lo que ninguna resuelve por completo: el problema de la información que cambia frecuentemente (métricas semanales, prioridades de sprint, estado de proyectos activos). Para eso necesitas combinar memoria persistente con actualizaciones manuales o integraciones dinámicas (Slack, Notion, Calendar), que están en desarrollo.
Antes de ver cómo la memoria persistente ataca el problema, conviene entender por qué la memoria nativa de las IAs (Claude memory, ChatGPT memory) no basta cuando lo que necesitas es precisión, no solo afinidad.
Imagínate que contratas a un asistente que al final de cada día escribe un párrafo resumiendo todo lo que habéis hablado. Al día siguiente, para reconstruir lo que sabe sobre ti, relee todos sus párrafos anteriores y los resume en un párrafo nuevo. Repite el proceso cada día durante un año.
¿Qué queda al final?
Es el juego del teléfono aplicado a memoria. Cada iteración pierde un poco. En 3 meses no lo notas. En 12 meses pides algo específico y la respuesta es plausible pero inventada.
Claude memory es una fotografía de quién eres, borrosa en los bordes y que se difumina con el tiempo. Encuora es el archivo de lo que has hecho, con fechas y detalles, que sigue nítido años después. (Descubre aquí por qué Claude no recuerda)

Para saber qué sabes de ti, la fotografía basta. Para saber qué decidiste, qué prometiste, qué aprendiste — hace falta el archivo.
La memoria persistente no es "guardar texto para leerlo después". Es una arquitectura distinta que cambia fundamentalmente cómo tu IA procesa contexto.
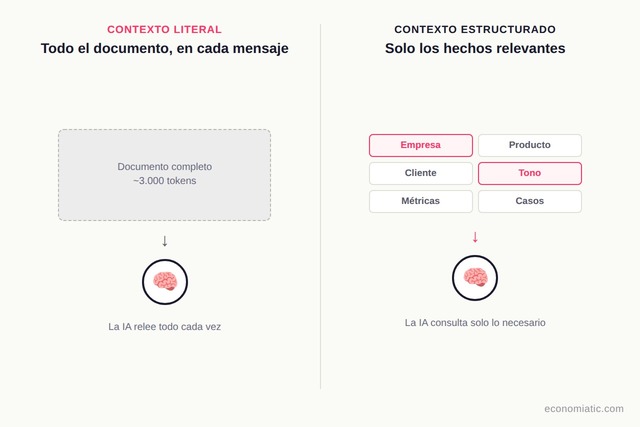
Contexto literal vs contexto estructurado. Los Projects de Claude almacenan texto literal: si tu documento tiene 3.000 tokens, esos 3.000 se envían completos en cada mensaje. Eficiente comparado con reescribir manualmente, pero sigue siendo redundante.

La memoria persistente bien diseñada almacena hechos estructurados que la IA consulta solo cuando los necesita.
En lugar de enviar un briefing completo de 2.000 tokens en cada conversación, la memoria guarda "empresa X fundada 2019, SaaS B2B, $2M ARR, cliente objetivo CFOs 50-200 empleados". Cuando preguntas algo irrelevante para tu consulta, la IA no lo carga. Cuando lo necesita, accede solo a esa información específica.
Analogía: tu asistente humano puede:
(A) leer un documento de 10 páginas cada vez que te reúnes
(B) tener una base de conocimiento mental y acceder solo a los hechos relevantes para cada conversación. La segunda escala mejor.
La frase más valiosa que tu asistente puede decir es "no lo sé". Un sistema bien calibrado no solo guarda lo que sabes; registra explícitamente lo que no has compartido. Si preguntas sobre un proyecto nunca mencionado, en lugar de inventar responde "no tengo información sobre ese proyecto". Eso reduce alucinaciones.
Por qué funciona en cualquier IA con MCP. El Model Context Protocol de Anthropic es un estándar abierto que permite a las IAs conectarse con fuentes externas sin integración custom por proveedor. Si usas Claude hoy y cambias a ChatGPT mañana, tu memoria persistente sigue funcionando porque ambas leen el mismo contexto. Tu conocimiento se va contigo si cambias de IA. Herramientas como Encuora — actualmente en beta abierta — implementan este protocolo para ofrecer portabilidad real entre modelos.
Mejor contexto, no más contexto. La memoria persistente envía la información correcta, cuando se necesita, sin redundancia. Eso reduce tokens, mejora precisión y escala sin fricción adicional.
💡 ¿Quieres que tu IA recuerde sin repetir contexto cada vez?
Encuora añade memoria persistente a Claude y ChatGPT simultáneamente. Configuras tu contexto una vez — quién eres, en qué trabajas, tu estilo — y está disponible en todas tus conversaciones, en todas tus IAs, sin repetirte nunca más.
Beta abierta gratuita. Únete como beta tester → encuora.com
Tienes el porqué claro. Vamos a la práctica con capturas reales del flujo. La parte mecánica (pasos 1 a 5) la haces una sola vez por cada cerebro que crees; lo que dura es el onboarding del paso 6, donde cargas el contexto que la memoria va a guardar.
Para ahorrar tokens con memoria persistente de forma efectiva, sigue estos pasos:
Entra en tu panel de Encuora y pulsa "Nueva memoria". Se abre un modal pidiéndote un nombre.
Cada memoria es un cerebro independiente: contexto, hechos y preferencias separados. Puedes tener uno para tu trabajo, otro para inversión personal, otro para un cliente concreto.
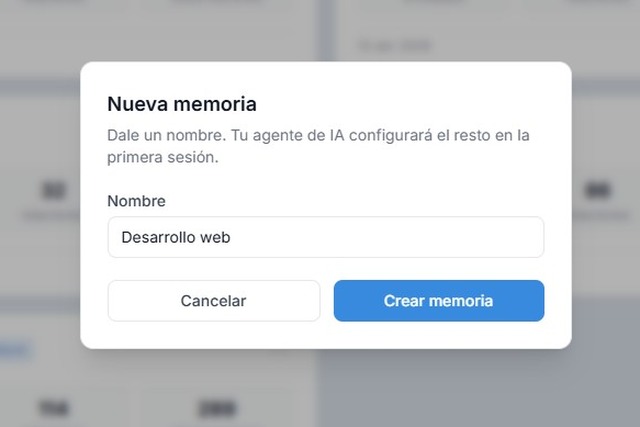
Al pulsar el botón aparece un modal con un campo Nombre. Si vas a montar un cerebro para tu trabajo de desarrollo web, llámalo "Desarrollo web". Si es para un cliente, "Cliente Acme".
El nombre es lo que verás luego al activarlo dentro de Claude o ChatGPT, así que conviene que sea reconocible a primera vista.
Pulsa "Crear memoria".
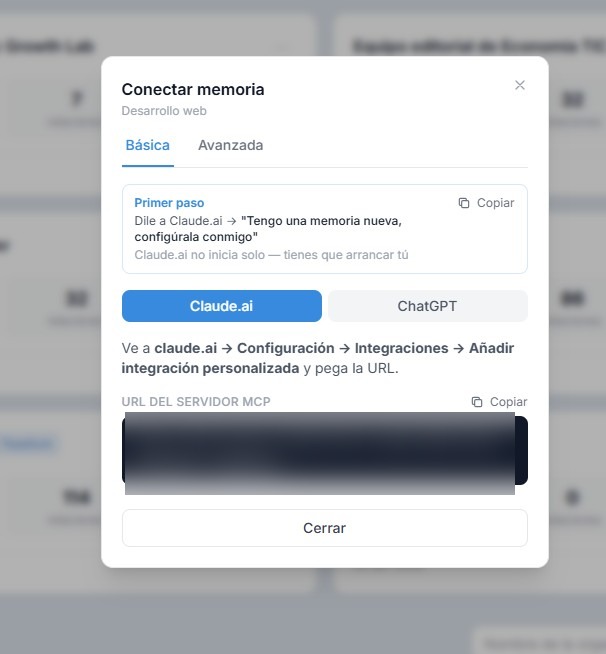
Verás la URL del servidor MCP — algo como https://brain.encuora.com/mcp?token=.... Cópiala con el botón de la derecha.
Esa URL es la dirección única de este cerebro: lo que vas a pegar en Claude (y en ChatGPT, si lo conectas también) para que pueda leer y escribir en él.
Fíjate en el bloque "Primer paso" del modal: cuando termines la configuración técnica, tendrás que decirle literalmente a Claude "Tengo una memoria nueva, configúrala conmigo". Lo veremos en el paso final.
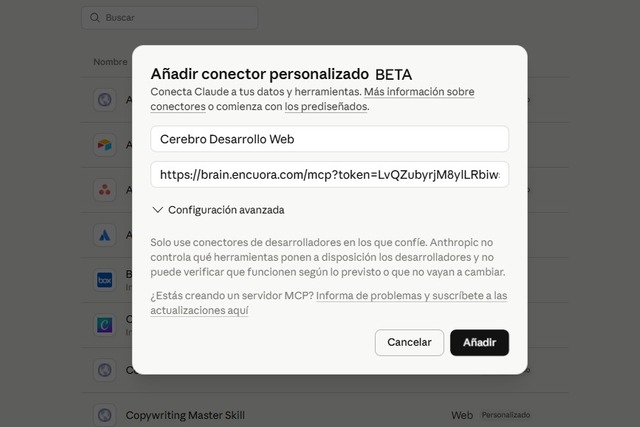
En Claude.ai, ve a Configuración → Integraciones → Añadir integración personalizada. Aparece este modal.
Rellena los dos campos:
Nombre: el mismo que le pusiste a tu memoria, con el prefijo "Cerebro" para distinguirlo rápido del resto de conectores (ej. "Cerebro Desarrollo Web").
URL: pega la del paso anterior.
Pulsa "Añadir". Claude registra el conector, pero todavía no lo está usando.
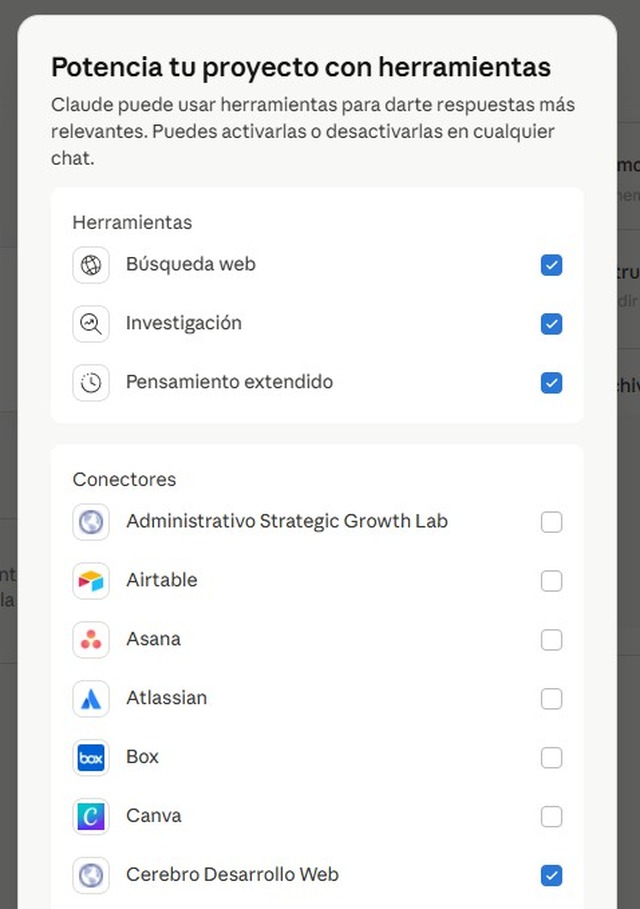
Marca su casilla. Solo con la casilla activa Claude puede leer y escribir en tu memoria desde las conversaciones de ese proyecto.
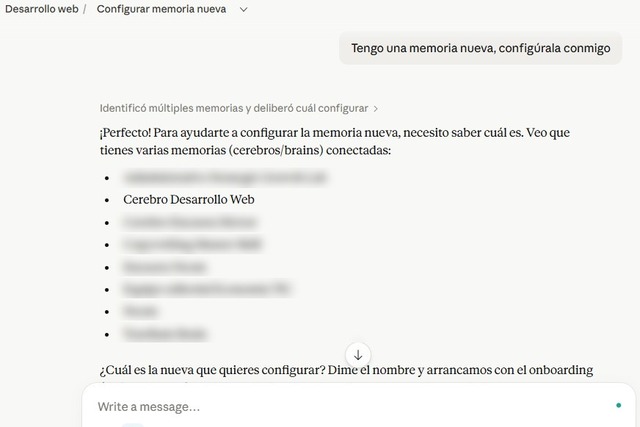
Esto es lo que diferencia Encuora de pegar texto en un Project: tu memoria está vacía, y tienes que rellenarla. Pero no a mano — hablando con Claude.
Abre un chat dentro del proyecto y escribe literalmente:
Tengo una memoria nueva, configúrala conmigo
Claude detecta los cerebros conectados, te pregunta cuál vas a configurar y arranca un onboarding guiado. Te va pidiendo los hechos estables que quieres que recuerde — quién eres, qué haces, con qué stack trabajas, tus clientes, tu tono de comunicación, lo que sea relevante para esa memoria.
Ejemplo: Marta es freelance de marketing. En su memoria guarda sus 3 clientes principales con sus sectores (startup fintech, e-commerce B2C, SaaS B2B), su tono habitual (directo, sin jerga), y sus dos plantillas más usadas (email de seguimiento, propuesta de campaña).
Cuanto más contexto cargues durante el onboarding, menos tendrás que repetir en sesiones futuras.
Abre un chat nuevo dentro del mismo proyecto — uno totalmente en blanco, sin nada que ver con el onboarding. Lanza una pregunta que requiera que la IA conozca quién eres, qué haces o tus preferencias.
En el caso de Marta: "Redáctame un email de seguimiento para mi cliente fintech sobre la propuesta que les envié la semana pasada". Si Claude aplica el tono que ella cargó (directo, sin jerga), reconoce el sector del cliente y usa la estructura de su plantilla habitual sin que se lo recuerde, la memoria está conectada y funcionando.
Si responde de forma genérica, vuelve al chat de onboarding y refuerza el contexto que faltó. A partir de aquí, cada nueva conversación que abras dentro del proyecto carga el contexto automáticamente.
Y si conectas el mismo cerebro en ChatGPT (mismo flujo, otro paso 4 desde la configuración de ChatGPT), tu contexto te acompaña entre las dos IAs sin tener que duplicarlo.
Encuora está actualmente en beta abierta. Memoria personal disponible; memoria de equipo e integraciones directas (Slack, Notion, Calendar) en desarrollo.
Herramientas que prometen "reduce tu factura un 70% con memoria persistente": ignora los porcentajes concretos. No son falsos, pero son engañosos. El ahorro real al optimizar tokens depende de tres factores impredecibles:
Lo que sí esperar sin riesgo: el coste de cada conversación individual no debería subir. Peor caso (poco contexto repetido): no ahorras mucho pero tampoco pierdes. Mejor caso (mucho contexto repetido): ahorro notable. En todos los casos, la calidad mejora.
El mayor gasto invisible en tu factura de IA no está en las consultas complejas que le haces. Está en el contexto repetido: información estable que envías una y otra vez porque cada conversación empieza de cero. La memoria persistente ataca ese problema estructural, reduciendo redundancia sin comprometer calidad.
Tienes tres opciones con trade-offs distintos: memoria nativa (automática pero limitada), Projects de Claude (manual pero poderosa), memoria persistente multi-IA (automatizada y portable). Elige según tu caso de uso. Y si configuras cualquiera de las tres, no esperes porcentajes de ahorro garantizados. Espera esto: contexto mejor, respuestas más precisas, escalabilidad sin fricción.
Tu IA puede saber quién eres. Encuora hace que también recuerde lo que has hecho.
No todavía. Los sistemas de memoria persistente usan MCP, el protocolo de Anthropic para conectar IAs con herramientas externas. Google aún no ha habilitado soporte MCP en Gemini. Funciona con Claude y ChatGPT.
Depende del sistema que uses. Si usas Projects de Claude, esa memoria es exclusiva de Claude. Si usas un sistema multi-IA, tu memoria es portable: si dejas de usar Claude y te pasas a ChatGPT (o usas ambas), la memoria sigue funcionando. Tu conocimiento se va contigo si cambias de IA.
Memoria de equipo está en desarrollo. La funcionalidad individual (tu memoria personal) está disponible ahora; memoria colaborativa (compartir contexto con tu equipo) llegará próximamente en herramientas que soportan esta funcionalidad.
Depende del proveedor. Los sistemas serios almacenan tu memoria en servidores seguros y no la comparten con terceros. Pero si tu contexto incluye datos altamente sensibles (contraseñas, API keys, información financiera confidencial), no lo guardes en ninguna memoria externa. Usa esa información solo en conversaciones privadas.
Depende del proveedor. Projects de Claude está incluido en tu plan. Otras herramientas como Encuora están en beta abierta gratuita — puedes unirte como beta tester en encuora.com durante el programa beta.
No, se complementan. Projects es ideal si trabajas exclusivamente en Claude y quieres control manual total. La memoria persistente multi-IA es mejor si usas varias IAs o si tu contexto evoluciona rápido y prefieres actualizaciones automáticas.
Última revisión: Mayo 2026
Aviso: Este artículo contiene información general sobre optimización de tokens en modelos de IA. Los costes específicos y características mencionadas pueden variar según actualizaciones de los proveedores. Consulta siempre la documentación oficial de Anthropic, OpenAI y otros proveedores para información actualizada sobre pricing y funcionalidades.
