
El 65% de las empresas españolas ya utiliza inteligencia artificial en algún punto del proceso de selección de personal, según el portal Infojobs recogido por la Universitat Oberta de Catalunya1. En paralelo, el 66% de los profesionales encuestados a nivel global por HireVue en 2025 declara que no quiere que la IA tome decisiones finales de contratación2. Las dos cifras conviven y no deberían: la herramienta ya está dentro, pero quien la usa no se fía de ella para lo importante.
Esa tensión es donde nacen casi todas las conversaciones empresariales sobre sesgos algorítmicos. Los modelos están desplegados, las decisiones automatizadas se toman a escala, y los responsables operativos no saben dónde mirar para saber si el sistema está discriminando o no. La narrativa pública oscila entre dos extremos igual de inútiles:
Lo esencial
- Los sesgos algorítmicos no son un fallo técnico erradicable: son una consecuencia estructural de aprender de datos históricos que reflejan decisiones humanas previas. La pregunta no es cómo eliminarlos, sino quién audita, con qué criterio y con qué consecuencias.
- Los casos documentados (Amazon HR, Optum, Toeslagenaffaire, BOSCO) comparten un patrón: el sesgo no aparece en el código, aparece cuando un sistema opaco decide a escala y nadie supervisa la frontera entre dato y discriminación.
- La AI Act obliga desde el 2 de agosto de 2026 a transparencia y a cumplir los requisitos de los sistemas de alto riesgo (selección de personal, evaluación crediticia, acceso a servicios esenciales), pero la responsabilidad operativa sigue siendo de la empresa que despliega el modelo. Hay cuatro decisiones de gobernanza que no se pueden delegar al proveedor.
Falta lo de en medio: transparencia algorítmica suficiente para auditar, y un marco de decisión claro para quien tiene que desplegar la herramienta.
Las dos cosas son falsas en su versión simple.
La tesis de este artículo es más operativa: los sesgos algorítmicos no son un fallo del código que se pueda parchear, son una consecuencia estructural de aprender de datos históricos que reflejan decisiones humanas previas.
La pregunta correcta no es cómo eliminarlos, sino quién audita, con qué criterio y con qué consecuencias cuando el sistema se equivoca. Y esa pregunta ya no es opcional: la AI Act europea entra en vigor por bloques durante 2026.
Un sesgo algorítmico es una desviación sistemática en las decisiones de un sistema automatizado que perjudica de forma consistente a un grupo de personas en función de una característica como género, etnia, edad, código postal o nivel socioeconómico. Aparece cuando el modelo aprende patrones de datos históricos que ya contenían esas desigualdades, o cuando el diseño del sistema confunde un proxy con la variable real que pretendía medir.
La intuición habitual —«si quito la variable género del input, el algoritmo no podrá discriminar»— es incorrecta. Los modelos modernos de machine learning detectan correlaciones que actúan como proxies de la variable protegida aunque esa variable no esté presente: el barrio de residencia puede informar sobre etnia, el historial de actividad sobre género, la duración del nombre sobre origen geográfico. Eliminar la variable explícita no elimina la señal.
Tres fuentes generan la mayor parte de los sesgos que se observan en producción:
Ninguna de las tres se resuelve con una línea de código. Las tres requieren decisiones humanas sobre qué medir, qué optimizar y qué tolerar.
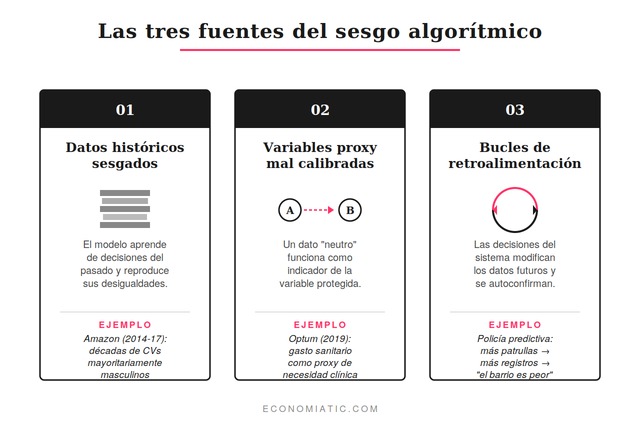
Los casos académicos suelen quedarse en la abstracción. Los cuatro que siguen comparten un rasgo: están documentados, tuvieron consecuencias reales y muestran el patrón completo —del dato a la decisión y de la decisión al daño.
Amazon desarrolló entre 2014 y 2017 una herramienta interna para puntuar candidaturas a puestos técnicos. El sistema penalizaba los currículums que contenían la palabra «women’s» (como «women’s chess club») y degradaba a graduadas de dos universidades exclusivamente femeninas3. Cuando el equipo descubrió el problema, intentó corregirlo, no consiguió garantías de que el sesgo no reapareciera por otras vías y abandonó la herramienta en 2017. Reuters publicó la historia en octubre de 2018.
La pieza interesante no es que ocurriera, es por qué ocurrió. El modelo se había entrenado con currículums recibidos por Amazon durante una década. En ese histórico, los puestos técnicos los habían ocupado mayoritariamente hombres. El algoritmo no fue «machista» por decisión: aprendió que el patrón de candidato exitoso era masculino y lo proyectó hacia adelante. Quitar la variable género no bastó porque el lenguaje del currículum contenía la señal.
Optum, filial de UnitedHealth, utilizaba un algoritmo para identificar a pacientes que necesitaban programas de cuidados adicionales. Un estudio publicado en Science en 2019 demostró que el sistema asignaba sistemáticamente menos recursos a pacientes negros con el mismo nivel de enfermedad que los pacientes blancos4. El algoritmo no usaba la etnia como variable; usaba el gasto sanitario previo como proxy de necesidad. Como los pacientes negros habían tenido históricamente menor acceso a la sanidad, su gasto previo era menor, y el modelo concluía que necesitaban menos cuidados.
Corregir el proxy —medir necesidad clínica directamente, no gasto— habría elevado el porcentaje de pacientes negros con acceso a cuidados adicionales del 17,7% al 46,5%. Una reducción del 84% en el sesgo del sistema, conseguida sin tocar el modelo: solo cambiando qué se le pedía optimizar.
Entre 2005 y 2019, la agencia tributaria neerlandesa utilizó un sistema automatizado de detección de fraude en las ayudas para guardería. El modelo señaló a aproximadamente 26.000 familias como sospechosas de fraude basándose, entre otros factores, en la nacionalidad y la doble nacionalidad. Las familias afectadas tuvieron que devolver de golpe importes de decenas de miles de euros que el Estado les había abonado años antes5.
El daño documentado fue grave: familias en bancarrota, separaciones forzadas, niños retirados temporalmente a sus padres por insolvencia. El 15 de enero de 2021, el gobierno de Mark Rutte presentó su dimisión por el escándalo, tras la publicación del informe parlamentario «Ongekend Onrecht» («Unprecedented Injustice») en diciembre de 2020. El sistema no había sido auditado externamente durante los 14 años de operación.
BOSCO es la aplicación informática del Ministerio para la Transición Ecológica que las comercializadoras eléctricas utilizan para verificar si un solicitante cumple los requisitos del bono social. La Fundación Civio detectó en 2018 que el sistema denegaba el bono a personas que, según la ley, deberían tener derecho a él. Pidió acceso al código fuente. La Administración lo denegó. Civio recurrió.
El 11 de septiembre de 2025, el Tribunal Supremo dictó la sentencia 1119/2025, que condena a la Administración del Estado a facilitar a la Fundación Ciudadana Civio el acceso al código fuente de la aplicación informática BOSCO6. La sentencia crea jurisprudencia sobre transparencia algorítmica en España: el acceso al código fuente de aplicaciones públicas que toman decisiones automatizadas sobre derechos sociales es una concreción del derecho constitucional de acceso a la información. A mayo de 2026, el código no ha sido entregado todavía.
El patrón común a los cuatro casos no está en el código. Está en el procedimiento: un sistema opaco, una decisión a escala, una variable proxy mal elegida o un dato histórico mal calibrado, y nadie auditando hasta que el daño es público. La falta de transparencia algorítmica no es un detalle técnico secundario: es la condición que permite que el sesgo se sostenga durante años sin que nadie pueda demostrarlo.
Aquí hay un mito que conviene desmontar antes de seguir: la idea de que con suficiente cuidado técnico se puede construir un algoritmo «justo». No se puede, y la razón es matemática, no de implementación.
Kleinberg, Mullainathan y Raghavan demostraron en 2017 que existen al menos tres definiciones razonables de equidad algorítmica que un sistema no puede cumplir simultáneamente salvo en casos triviales7. Mejorar el cumplimiento de una empeora necesariamente otra. La traducción operativa es incómoda: cualquier empresa que despliegue un modelo en una decisión sensible está eligiendo una definición de equidad, lo sepa o no.
Las tres definiciones, traducidas sin jerga:
| Definición de equidad | Qué garantiza | Qué sacrifica |
|---|---|---|
| Calibración | Que una puntuación del 0,8 signifique lo mismo —probabilidad real del 80%— para todos los grupos | Puede aceptar tasas distintas de falsos positivos y falsos negativos entre grupos |
| Equilibrio en falsos positivos | Que el porcentaje de personas marcadas incorrectamente como riesgo sea igual en todos los grupos | Sacrifica calibración: la puntuación deja de significar lo mismo entre grupos |
| Equilibrio en falsos negativos | Que el porcentaje de personas marcadas incorrectamente como bajo riesgo sea igual en todos los grupos | Sacrifica calibración por el otro extremo |
La consecuencia práctica es que la pregunta «¿este sistema es justo?» está mal planteada. La pregunta correcta es «¿qué tipo de error estamos dispuestos a aceptar y para qué grupo?». Esa es una decisión política y ética, no técnica. El equipo de ingeniería puede implementar la que se elija, pero no puede elegirla por la organización.
El Reglamento Europeo de Inteligencia Artificial (AI Act) entró en vigor por fases en 2024-2026. Para sistemas de IA clasificados como «de alto riesgo» —y los que se usan en selección de personal, evaluación crediticia, acceso a servicios esenciales y decisiones administrativas lo son— hay dos artículos especialmente relevantes.
El artículo 10 exige que los datos de entrenamiento, validación y test sean «pertinentes, suficientemente representativos y, en la medida de lo posible, libres de errores y completos teniendo en cuenta la finalidad prevista»8. Obliga también a examinar los conjuntos de datos para detectar posibles sesgos algorítmicos que puedan afectar a la salud, la seguridad o los derechos fundamentales, y a adoptar medidas adecuadas para mitigarlos. No exige eliminarlos —reconoce implícitamente que no siempre es posible—; exige documentarlos y gestionarlos.
El artículo 50 introduce obligaciones de transparencia para sistemas que interactúan con personas físicas, generan contenido sintético o se usan en categorización biométrica y reconocimiento emocional. Es aplicable desde el 2 de agosto de 2026.
Lo que la AI Act no resuelve, y que sigue siendo decisión de la empresa, es cómo se traducen estas obligaciones en gobernanza interna concreta. El reglamento fija un marco; cada organización tiene que construir el procedimiento que cumple con él. Una pyme española que utilice una herramienta de IA contratada a un proveedor externo no puede limitarse a confiar en que el proveedor cumple la normativa: la responsabilidad del despliegue es del usuario del sistema, no solo del desarrollador.
Si un proveedor te dice «nuestro modelo está libre de sesgos algorítmicos», o no entiende lo que vende o está vendiendo una promesa que no puede cumplir. La gestión real de los sesgos algorítmicos en una empresa pasa por cuatro decisiones que el cliente final tiene que tomar internamente, aunque la tecnología venga de fuera:
Las cuatro a continuación, con el detalle operativo.
No todas las decisiones se prestan al mismo nivel de delegación. Un sistema que ordena candidaturas para que un humano las revise es distinto de un sistema que descarta candidaturas automáticamente. Un score que ayuda a priorizar la atención sanitaria es distinto de uno que niega el acceso. La primera decisión de gobernanza es trazar esa línea: dónde el algoritmo recomienda y un humano decide, dónde el algoritmo decide y un humano puede revisar, dónde el algoritmo no debería intervenir.
La línea no es la misma para todas las empresas y para todos los casos. Lo que sí es común es que tiene que estar trazada explícitamente y por escrito antes de desplegar el sistema, no después del primer incidente.
Como se ha visto, no se puede optimizar a la vez calibración y equilibrio de tasas de error. Toca elegir. La elección depende del tipo de error que la empresa considere más grave en el contexto concreto: un falso negativo en detección de fraude tiene consecuencias distintas que un falso positivo en selección de personal.
Lo importante no es acertar a la primera con la métrica perfecta —no existe—. Lo importante es que la elección esté documentada, justificada y se pueda discutir externamente cuando alguien la cuestione.
Auditar internamente es necesario pero insuficiente. El sesgo de Optum se descubrió porque un equipo académico externo accedió a los datos; el de la Toeslagenaffaire, porque periodistas y diputados lo investigaron; el de BOSCO, porque Civio recurrió judicialmente. Ningún sistema sesgado de los documentados fue detectado primero por su propio equipo de auditoría interna.
La gobernanza real pasa por auditorías externas con cadencia definida, acceso a datos suficiente para que la auditoría sea significativa, y un canal claro para que personas afectadas puedan reclamar. Para una pyme, esto puede significar contratar una auditoría externa anual a un especialista; para una organización mayor, un equipo permanente de revisión.
Todos los sistemas se equivocan. La diferencia entre una organización que gestiona el sesgo y una que lo ignora se ve en lo que pasa cuando aparece el error: si hay un canal de reclamación accesible, si las decisiones son reversibles, si hay un humano con autoridad real para anular la decisión del sistema, si la empresa aprende del incidente o lo entierra.
La AI Act introduce el derecho a explicación para decisiones individuales basadas en sistemas de alto riesgo. Cumplir ese derecho exige que la empresa tenga preparado el procedimiento antes de la primera reclamación, no después.
Cuatro contraargumentos honestos antes de cerrar.
No toda IA empeora la equidad. Algunos estudios documentan que sistemas bien diseñados reducen ciertos sesgos humanos —fatiga del entrevistador, anclaje en el primer candidato, inconsistencia entre evaluadores—. El problema no son los sesgos algorítmicos como categoría, sino la IA opaca, no auditada y desplegada sin marco de gobernanza. Comparar «decisión algorítmica» con «decisión humana ideal» no es honesto: la comparación real es entre «decisión algorítmica con auditoría» y «decisión humana con sus propios sesgos sin auditoría».
Auditar también tiene costes. Una auditoría externa anual seria puede costar a una pyme entre varios miles y decenas de miles de euros, y exigir compartir datos con un tercero. Para algunas organizaciones, la respuesta racional puede ser no usar IA en decisiones sensibles, no auditarla todo lo posible.
El concepto de «grupo protegido» no es universal. Las definiciones de equidad asumen que los grupos relevantes están identificados de antemano. En la práctica, los efectos de un sistema pueden aparecer en intersecciones de variables (mujeres mayores de 50 con código postal X, por ejemplo) que ningún auditor anticipa. Detectar esos efectos requiere monitorización continua, no una sola auditoría.
Lo que este artículo no resuelve. No entra en las técnicas concretas de mitigación —reweighing, adversarial debiasing, post-procesado—. Esas son decisiones del equipo técnico una vez la organización ha tomado las cuatro decisiones de gobernanza. El orden importa: técnica sin gobernanza es ingeniería resolviendo problemas mal planteados.
Conclusiones clave
- Los sesgos algorítmicos no son un bug del código que se pueda parchear. Son una propiedad estructural de cualquier sistema que aprende de datos históricos generados por decisiones humanas. La pregunta empresarial correcta no es cómo eliminarlos, sino cómo gestionarlos.
- La equidad algorítmica perfecta es matemáticamente imposible en casos no triviales. Toda organización que despliegue IA en decisiones sensibles está eligiendo una definición de equidad por encima de otras, lo sepa o no. Hacer esa elección explícita es el primer acto de gobernanza serio.
- La AI Act fija el marco regulatorio europeo pero no construye la gobernanza interna. Cuatro decisiones siguen siendo de la empresa: qué decisiones admiten automatización, qué métrica de equidad se optimiza, quién audita externamente, y qué pasa cuando el sistema se equivoca.
- Los cuatro casos de sesgos algorítmicos documentados —Amazon, Optum, Toeslagenaffaire, BOSCO— comparten un patrón: opacidad más escala más ausencia de auditoría externa. La buena noticia es que ese patrón es prevenible. La mala es que los tres primeros tardaron años en salir a la luz.
Adoptar IA con criterio no significa ni rechazarla por miedo ni desplegarla por moda. Significa preguntarse, antes de cada caso de uso, qué decisión está delegando la organización, a quién afecta y cómo se va a revisar cuando se equivoque. Esas preguntas no las contesta el proveedor.
Un sesgo algorítmico es una desviación sistemática en las decisiones de un sistema automatizado que perjudica de forma consistente a un grupo de personas en función de una característica como género, etnia, edad o nivel socioeconómico. Aparece cuando el modelo aprende patrones de datos históricos que ya contenían esas desigualdades o cuando se usa una variable proxy mal calibrada. Los ejemplos más documentados —Amazon, Optum, Toeslagenaffaire, BOSCO— comparten ese mismo mecanismo. No es un fallo de programación: es una propiedad estadística del proceso de aprendizaje.
No exactamente: el sesgo es la propiedad estadística del sistema; la discriminación es el efecto jurídicamente relevante sobre personas concretas. Un sistema puede ser sesgado sin generar discriminación si la decisión que produce no afecta a derechos protegidos. La discriminación algorítmica es lo que ocurre cuando ese sesgo se cruza con una decisión que afecta a acceso a empleo, crédito, servicios sanitarios o prestaciones.
Si tu empresa utiliza IA en selección de personal, es muy probable que el sistema esté clasificado como de «alto riesgo» según el AI Act y le aplique el artículo 10 sobre datos representativos y libres de sesgos. La responsabilidad recae también en quien despliega el sistema, no solo en el proveedor. Esto exige documentación interna, auditoría y procedimientos de reclamación, aunque la herramienta sea de un tercero.
Sí, parcialmente: existen técnicas de auditoría de caja negra que evalúan el comportamiento del sistema sin acceder al código, midiendo outputs sobre inputs controlados. No sustituyen una auditoría completa con acceso al código, pero permiten detectar disparidades evidentes entre grupos. Para sistemas críticos, conviene exigir contractualmente al proveedor el acceso necesario para auditorías serias.
Depende del diseño y la gobernanza del sistema: la IA bien auditada puede reducir ciertos sesgos humanos como la inconsistencia entre evaluadores; la IA opaca y sin auditar tiende a amplificarlos al aplicarlos a escala. La comparación honesta no es entre algoritmo y juicio humano ideal, sino entre algoritmo con auditoría y juicio humano con sus propios sesgos no documentados.
No se pueden evitar por completo, pero sí se pueden gestionar: las cuatro decisiones de gobernanza descritas arriba (qué automatizar, qué métrica de equidad elegir, quién audita, qué hacer con los errores) son el marco operativo mínimo. A ello se añade exigir al proveedor transparencia algorítmica suficiente para auditar el sistema, documentar internamente cada decisión sensible y formar al equipo que opera con la herramienta. Eliminar el riesgo es imposible; reducirlo a un nivel aceptable y trazable, sí.
Documenta el hallazgo, suspende o limita el uso del sistema en las decisiones sensibles mientras se investiga, y activa el canal de reclamación para las personas potencialmente afectadas. Después, contrasta el hallazgo con el proveedor —exigiendo evidencia, no afirmaciones— y revisa si las decisiones tomadas durante el periodo afectado pueden y deben revertirse. Bajo la AI Act, la trazabilidad de estas acciones es exigible.
