
El corrector del móvil que adivina la siguiente palabra, las recomendaciones de Netflix, el filtro que aparta el spam y el propio ChatGPT tienen un mismo motor por debajo: el machine learning.
Entender qué es el machine learning ayuda a distinguir lo que estos sistemas hacen de verdad —encontrar patrones en datos— de lo que la conversación pública les atribuye.
No piensan ni «aprenden» como una persona; ajustan números hasta que aciertan más de lo que fallan.
Lo importante
- El machine learning (aprendizaje automático) es la rama de la IA que permite a un programa aprender patrones a partir de datos, en lugar de seguir reglas escritas a mano para cada caso.
- No es lo mismo que una red neuronal: el deep learning es solo una de sus técnicas. El ciclo real es datos → variables → entrenamiento → modelo → inferencia, con el sobreajuste (overfitting) como riesgo central.
- Hay tres familias —aprendizaje supervisado, no supervisado y por refuerzo— y en España el 21,1 % de las empresas de 10+ empleados ya usaba IA en el primer trimestre de 2025, según el INE.
Este artículo parte de la definición, explica cómo funciona el aprendizaje automático sin saltarse los pasos incómodos, repasa sus tipos y aplicaciones, y aterriza el concepto en la economía española con datos oficiales.
Sin alarmismo y sin promesas de revolución: solo el funcionamiento real y por qué importa.
El machine learning (aprendizaje automático) es la rama de la inteligencia artificial que permite a un sistema aprender a resolver una tarea a partir de datos, en lugar de ser programado con reglas explícitas para cada caso.
En vez de decirle al ordenador qué hacer paso a paso, le mostramos ejemplos y dejamos que infiera por sí mismo los patrones que los relacionan1.
La idea no es nueva. En 1959, Arthur Samuel —investigador de IBM que construyó un programa capaz de jugar a las damas mejor que su propio creador— acuñó el término y lo definió como «el campo de estudio que da a los ordenadores la capacidad de aprender sin ser programados explícitamente»2.
Casi cuarenta años después, Tom Mitchell le dio una formulación más operativa: un programa aprende de la experiencia E respecto a una tarea T y una medida de rendimiento P si su desempeño en T, medido por P, mejora con E3. En cristiano: el sistema lo hace mejor cuantos más datos ve.
Conviene desinflar una idea heredada. Cuando se dice que las máquinas «aprenden por sí solas», no hay nada parecido a la comprensión humana. Lo que ocurre es estadística aplicada a gran escala: el modelo detecta correlaciones en millones de ejemplos y las usa para hacer predicciones sobre datos nuevos.
Por eso, si los datos de partida arrastran prejuicios, el modelo los hereda; es el origen de los sesgos algorítmicos que afectan a decisiones empresariales y sociales.
La relación entre los tres términos es jerárquica, como muñecas rusas.
La inteligencia artificial es el campo más amplio: todo intento de que una máquina realice tareas que asociamos a la inteligencia.
Dentro de la IA, el machine learning es el conjunto de métodos que consiguen ese comportamiento a base de datos en lugar de reglas.
Y dentro del machine learning, el deep learning (aprendizaje profundo) es una técnica concreta, basada en redes neuronales de muchas capas.
IA ⊃ machine learning ⊃ deep learning
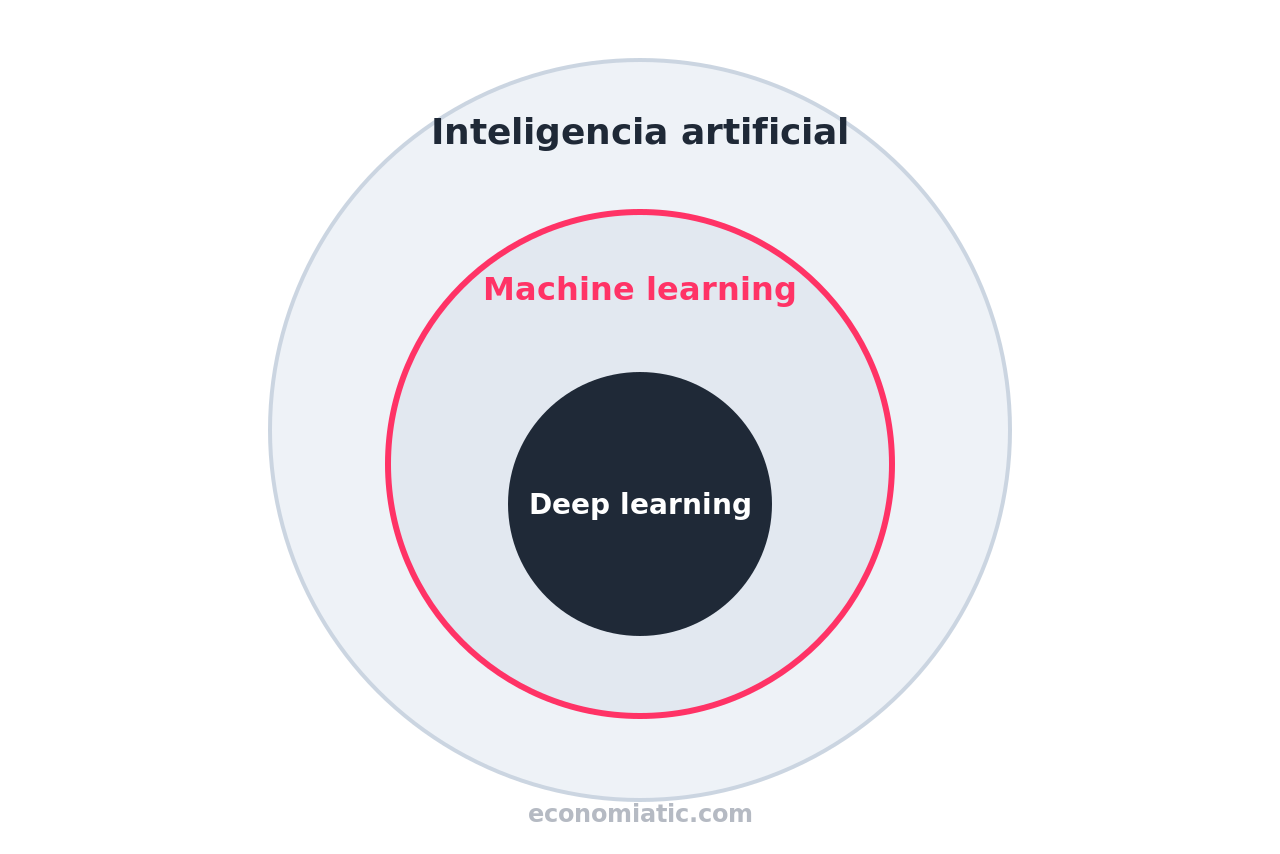
Esta distinción importa porque es la fuente de la confusión más común: no, el machine learning no es lo mismo que una red neuronal.
Las redes neuronales son una herramienta dentro del ML, la que sostiene al deep learning, pero buena parte del aprendizaje automático que funciona a diario en empresas usa métodos mucho más simples —y a menudo más interpretables— que nada tienen que ver con neuronas artificiales.
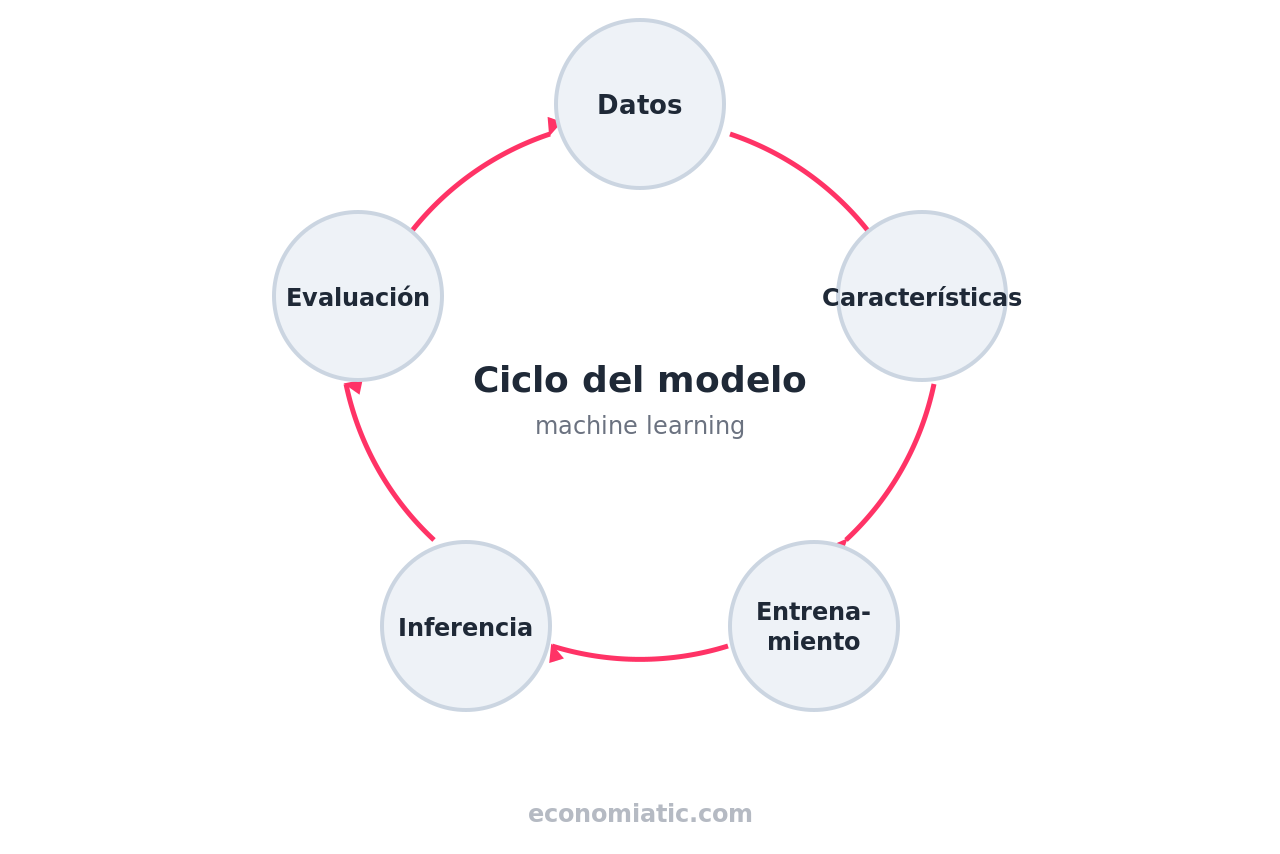
El machine learning funciona como un ciclo de cinco pasos: se reúnen datos, se traducen a variables medibles, se entrena un modelo con una parte de esos datos, se evalúa con la parte restante y, si supera la prueba, se pone a hacer predicciones sobre casos nuevos.
No hay magia ni una «red neuronal» detrás de cada caso: hay un proceso medible y repetible.
Veámoslo por partes, con un ejemplo cotidiano —un filtro de spam—:
La diferencia con la programación tradicional es de raíz.
En un programa clásico, una persona escribe las reglas («si el correo contiene esta palabra, márcalo como spam»). En machine learning, el programa deduce las reglas a partir de los ejemplos.
Por eso es tan útil en problemas donde las reglas serían imposibles de enumerar a mano: reconocer una cara, traducir un idioma o predecir qué película te gustará.
Para saber si un modelo ha aprendido de verdad o solo ha memorizado, los datos se reparten antes de entrenar. La práctica habitual es separar en torno al 80 % para entrenamiento y el 20 % restante para prueba, de modo que el modelo se evalúe siempre con casos que no ha visto4.
Técnicas como la validación cruzada (k-fold) refinan ese reparto rotando qué porción se usa para probar.
El riesgo que esto previene tiene nombre: el sobreajuste (overfitting). Un modelo sobreajustado memoriza los ejemplos de entrenamiento —incluido su ruido y sus casualidades— en lugar de captar el patrón general.
Acierta casi siempre con los datos que ya conoce y falla con los nuevos. Es el estudiante que se sabe de memoria los exámenes de años anteriores pero no entiende la asignatura.
El equilibrio contrario, el subajuste (underfitting), ocurre cuando el modelo es demasiado simple para captar el patrón.
El oficio del aprendizaje automático consiste, en buena medida, en navegar entre esos dos extremos.
Existen tres grandes familias de machine learning según cómo aprende el modelo: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo.
A ellas se suma una cuarta variante intermedia, el aprendizaje semisupervisado. La diferencia está en si los datos vienen etiquetados, en qué medida y en cómo recibe el sistema su retroalimentación.
En el aprendizaje supervisado se entrena el modelo con datos etiquetados: cada ejemplo lleva la respuesta correcta. Es como estudiar con un solucionario.
Dentro de esta familia hay dos tareas típicas: la clasificación (asignar una categoría: spam / no spam, perro / gato) y la regresión (predecir un número: el precio de una vivienda, la demanda de la semana que viene).
El reconocimiento facial es un ejemplo claro de aprendizaje supervisado: el sistema se entrena con imágenes etiquetadas con la identidad correcta.
Lo mismo ocurre con la detección de spam o el diagnóstico asistido por imagen.
Algoritmos habituales: regresión lineal y logística, árboles de decisión, random forest, máquinas de vectores de soporte (SVM) y k vecinos más cercanos (k-NN).
En el aprendizaje no supervisado, los datos no llevan etiquetas: el modelo debe encontrar estructura por sí mismo. No le decimos qué buscar; le pedimos que agrupe lo que se parece. La tarea estrella es el clustering (agrupamiento), que segmenta los datos en grupos con rasgos comunes.
Un caso típico es la segmentación de clientes: un comercio agrupa a sus compradores por patrones de consumo sin definir de antemano las categorías.
También se usa para detección de anomalías —transacciones bancarias fuera de lo normal— o para reducir la complejidad de conjuntos de datos enormes.
Algoritmos frecuentes: k-means y el análisis de componentes principales (PCA).
El aprendizaje por refuerzo entrena a un agente por ensayo y error: el sistema toma decisiones, recibe una recompensa cuando acierta y una penalización cuando falla, y ajusta su estrategia para maximizar la recompensa a largo plazo.
No hay un solucionario; hay consecuencias.
Es el enfoque detrás de AlphaGo —el programa que venció al campeón mundial de Go—, de buena parte de la robótica y de los sistemas de conducción autónoma. También se usa para afinar el comportamiento de los grandes modelos de lenguaje a partir de la valoración humana.
El aprendizaje semisupervisado combina una pequeña cantidad de datos etiquetados con una gran masa de datos sin etiquetar.
Es útil cuando etiquetar es caro o lento —por ejemplo, marcar manualmente miles de radiografías— y permite aprovechar lo no etiquetado para mejorar un modelo que parte de pocos ejemplos con respuesta conocida.
Detrás de cada tipo de aprendizaje hay algoritmos concretos. No hace falta dominarlos para entender el concepto, pero conviene reconocer los nombres que más aparecen:
El machine learning sirve para automatizar tareas de predicción y clasificación a una escala imposible para una persona, y está presente en servicios que usamos sin notarlo. Estos son los usos más extendidos:
La oleada de IA generativa que estalló a partir de 2022 no es una tecnología ajena al machine learning: es machine learning llevado a una escala enorme.
Los grandes modelos de lenguaje (LLM) como los que mueven ChatGPT son modelos de deep learning entrenados sobre cantidades masivas de texto para predecir la siguiente palabra. Cuando le preguntas algo a un chatbot, estás usando un modelo de aprendizaje automático.
Entenderlo así también ayuda a interpretar sus límites.
Como todo modelo de ML, un LLM funciona por patrones estadísticos, no por comprensión: de ahí que pueda generar respuestas plausibles pero falsas. Es estadística sobre el lenguaje, no un oráculo.
El deep learning es un subtipo de machine learning basado en redes neuronales profundas. Comparten el principio —aprender de datos—, pero difieren en el tipo de datos que manejan, cuánta intervención humana requieren y qué recursos consumen. La tabla resume las diferencias prácticas:
| Criterio | Machine learning (clásico) | Deep learning |
|---|---|---|
| Tipo de datos | Sobre todo estructurados (tablas) | Sobre todo no estructurados (imágenes, audio, texto) |
| Ingeniería de variables | Manual: la persona define las features | Automática: la red extrae sus propias representaciones |
| Volumen de datos | Funciona con conjuntos moderados | Necesita grandes volúmenes |
| Coste computacional | Moderado | Alto (suele requerir GPU) |
| Interpretabilidad | Mayor (modelos más transparentes) | Menor (modelos «caja negra») |
Conviene matizar las fechas que a veces se repiten. El machine learning no «nació en los 80»: sus bases se remontan a los años 50 con Samuel, y maduró durante décadas. El deep learning tampoco apareció de la nada en 2010; sus fundamentos teóricos son anteriores y lo que llegó hacia 2012 fue su despegue práctico, gracias a más datos y a hardware (GPU) capaz de entrenar redes grandes.
La adopción del machine learning y, en general, de la IA en el tejido empresarial español crece con rapidez, pero parte de una base baja y mayoritariamente experimental.
Según el INE, el 21,1 % de las empresas de 10 o más empleados utilizaba inteligencia artificial en el primer trimestre de 2025, lo que supone un incremento de 8,7 puntos respecto al año anterior5.
El Banco de España, con su propia encuesta de actividad empresarial (EBAE), sitúa la cifra en torno al 20 % y aporta un matiz importante: en la mayoría de las empresas el uso de la IA sigue en fase experimental, más como exploración que como proceso consolidado6.
La adopción se concentra en los servicios tecnológicos y en empresas grandes, productivas y jóvenes, mientras que las pymes y los sectores tradicionales quedan rezagados.
Los principales frenos que identifica son la falta de personal cualificado, los costes de implantación y la disponibilidad de datos.
La lectura económica es sobria, sin triunfalismo. España ha pasado en pocos años de una adopción marginal a que una de cada cinco empresas medianas y grandes use IA, pero la brecha por tamaño es notable y el grueso del uso todavía no se ha traducido en transformación profunda de los procesos.
El machine learning es ya una herramienta corriente en las grandes; en buena parte del tejido productivo, una asignatura pendiente.
El machine learning dejó de ser un tecnicismo de laboratorio para convertirse en la infraestructura silenciosa de los servicios que usamos cada día y, cada vez más, del tejido empresarial.
Su funcionamiento no es misterioso: reúne datos, ajusta un modelo y predice, con el sobreajuste como límite constante y los sesgos de los datos como advertencia permanente.
Quien entiende que «aprender» aquí significa encontrar patrones —no comprender— está mejor preparado para usar estas herramientas con criterio, ni con fe ciega ni con miedo.
Es la rama de la inteligencia artificial que permite a los ordenadores aprender patrones a partir de datos, sin programarlos con reglas explícitas para cada tarea. En lugar de escribirle al sistema qué hacer paso a paso, se le muestran ejemplos y deduce por sí mismo cómo resolver casos nuevos.
La inteligencia artificial es el campo general; el machine learning es uno de los métodos que la hacen posible. La relación es jerárquica: la IA contiene al machine learning, y este contiene al deep learning. Todo machine learning es IA, pero no toda IA es machine learning.
El deep learning es un subtipo de machine learning basado en redes neuronales profundas. Trabaja sobre todo con datos no estructurados —imágenes, audio, texto—, extrae sus propias variables y necesita más datos y más potencia de cálculo que el machine learning clásico.
Sí: los grandes modelos de lenguaje como el que mueve ChatGPT son modelos de machine learning, en concreto de deep learning. Se entrenan sobre enormes volúmenes de texto para predecir la siguiente palabra, y por eso pueden generar respuestas plausibles aunque a veces incorrectas.
No para entenderlo, sí para implementarlo. El concepto se comprende sin escribir una línea de código; para construir modelos, Python es el lenguaje de referencia por su ecosistema de librerías especializadas.
