
⚠️ Soy cofundador de Encuora. Este artículo no es una review imparcial: es mi análisis honesto del producto que construyo en Teselium con Salva y Carlos, incluyendo sus límites actuales. Léelo con esa lente.
Salva fue el primero en darse cuenta. Llevaba semanas observando un patrón en su trabajo con Claude:
Cada conversación nueva empezaba igual. Diez minutos contándole quiénes éramos, en qué proyecto estábamos, con qué clientes, con qué tono escribíamos. Diez minutos antes de empezar a trabajar de verdad.
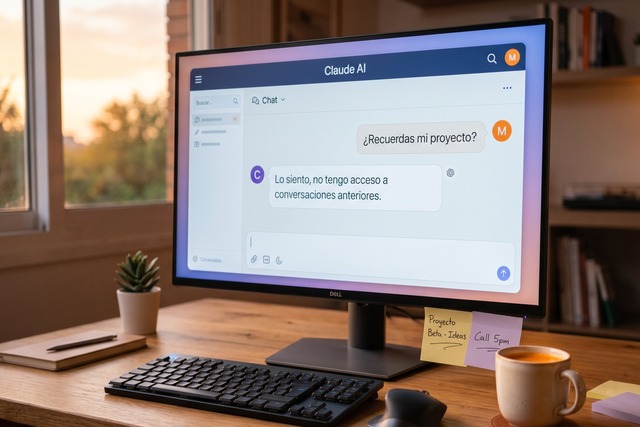
Lo peor no era la repetición. Lo peor era que, a mitad de una conversación larga, Claude empezaba a olvidar el contexto que él mismo había cargado. Salva tenía que recordárselo. Y a veces, al recordárselo, Claude se liaba más todavía: mezclaba detalles de proyectos distintos o daba consejos basados en información que ya no estaba en su ventana de contexto.
Cuando Salva habló con Carlos —nuestro tercer cofundador en Teselium— el diagnóstico fue rápido:
Este no es un problema de prompts, es un problema de arquitectura.
Las IAs de hoy no están diseñadas para acumular conocimiento sobre ti; están diseñadas para responder preguntas aisladas con la mayor plausibilidad posible.
❤️Así nació Encuora. Primero como herramienta interna para usar nosotros mismos en Teselium, después como producto.
Considera lo que sigue como mi opinión sobre Encuora desde dentro:
👉 lo bueno, lo regular y lo que todavía no funciona.
La memoria persistente es la capacidad de un sistema de IA para conservar información sobre ti entre sesiones distintas.
Es lo opuesto a la memoria por defecto de la mayoría de IAs: cuando cierras la conversación, todo lo que les has contado se evapora.
Para entenderla, conviene distinguir tres conceptos:
RECOMENDADO
Si quieres profundizar en el concepto, visita el siguiente artículo:
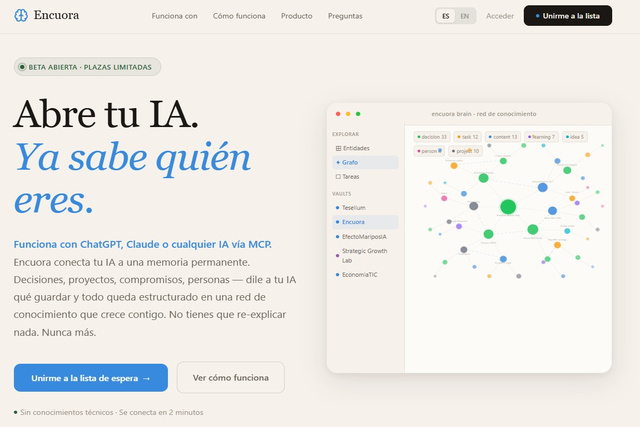
Encuora es una memoria persistente extractiva multi-IA. En tres palabras: tu memoria, contigo, en cualquier IA.
Lo construimos en Teselium, la división de IA de nuestra empresa Strategic Growth Lab. La estamos usando primero en nuestros propios proyectos antes de cualquier expansión externa. Lo que no funciona para nosotros, no llega al producto.
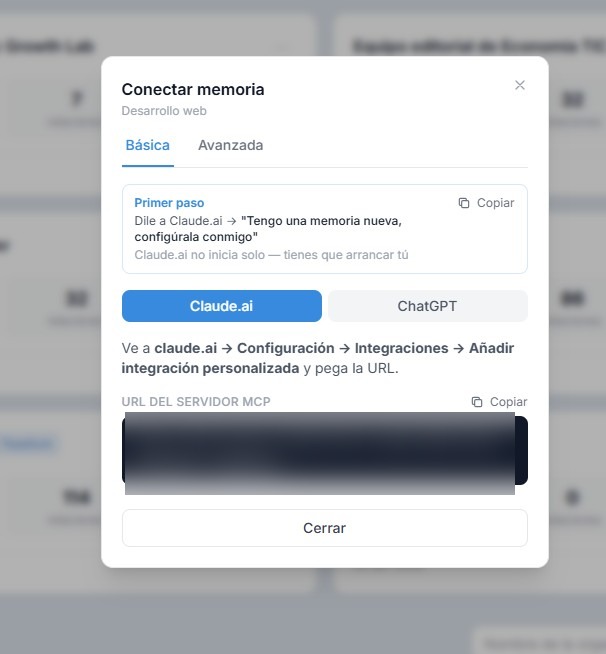
Actualmente estamos en beta abierta y gratuita durante toda la beta. Puedes acceder inscribiéndote con tu email en encuora.com (las nuevas plazas se abren por turnos)
Lo que Encuora NO es:
Aquí me voy a mojar como cofundador. La arquitectura tiene tres capas:
Encuora almacena tu información como un grafo de Entidades (personas, empresas, proyectos), Observaciones (hechos sobre cada entidad) y Relaciones (cómo se conectan). Claude no carga 5.000 tokens de contexto entero —carga solo los hechos relevantes a tu pregunta. Aquí lo explico con números aplicado a Claude.
Un token es aproximadamente una sílaba o palabra corta; 800 tokens son alrededor de 600 palabras. La memoria persistente ahorra tokens al enviar solo los hechos relevantes.
MCP (Model Context Protocol) es un estándar abierto de Anthropic que permite que cualquier herramienta se conecte a cualquier IA sin integraciones a medida. Hoy soportado por Claude y ChatGPT. Gemini lo tenemos en el roadmap, pero este LLM aún no tiene acceso a través de MCP.
Encuora es extractiva en la recuperación: el dato que recibe tu IA es el que tú metiste, literal. Pero el LLM sigue siendo generativo en la respuesta.
Lo que ganas es que los hechos vienen de la fuente correcta. Reduces la alucinación en datos, aunque no la eliminas en redacción.

Esta es la sección más larga del artículo. Si te quedas con un solo bloque, que sea este.
Claude memory genera un resumen generativo de tus conversaciones que pierde detalle con cada actualización. En 3 meses no lo notas; en 12 meses pides algo específico y la respuesta es plausible pero inventada. Aquí lo explico en detalle.
Encuora no resume, archiva. Sin pérdida.
Projects inserta el texto completo en cada conversación. Si tu briefing tiene 3.000 tokens, esos 3.000 se envían enteros, todo el rato.
Encuora consulta solo los hechos relevantes a la pregunta.
ChatGPT memory vive dentro de OpenAI. Si cambias de IA, ese contexto se queda allí. Encuora vive en servidores propios y se conecta vía MCP a cualquier IA compatible. Tu memoria viaja contigo.
Notion y Obsidian son segundos cerebros que tú consultas. Encuora está pensado para que tu IA consulte sola, en el momento que lo necesita, sin que se lo pidas explícitamente.

Claude memory es una fotografía de quién eres, borrosa en los bordes y que se difumina con el tiempo. Encuora es el archivo de lo que has hecho, con fechas y detalles, que sigue nítido años después.
Para saber qué sabes de ti, la fotografía basta. Para saber qué decidiste, qué prometiste, qué aprendiste — hace falta el archivo.
| Alternativa | Cómo funciona | Limitación principal | Ventaja de Encuora |
|---|---|---|---|
| Claude memory | Resume conversaciones generativamente | Pierde detalle con el tiempo | Recupera el dato literal, sin reconstrucción |
| Projects (Claude) | Inserta texto completo en cada prompt | Solo Claude, contexto inflado | Multi-IA y consulta solo los hechos relevantes |
| ChatGPT memory | Memoria interna de OpenAI | Lock-in al cambiar de IA | Tu memoria es portable entre Claude, ChatGPT y otras |
| Notion / Obsidian | Lo consultas tú manualmente | El LLM no accede automáticamente | Tu IA consulta sola, sin que se lo pidas |
Antes empezaba cada conversación con Claude reescribiendo el sector, el tono y el cliente. Ahora tiene un cerebro por cliente y su IA ya sabe con quién está trabajando esa semana.
Tengo un cerebro que guarda el Manual de marca de Encuora, las reglas, las decisiones editoriales, etc.
Cuando empiezo un artículo nuevo del cluster, mi IA ya conoce las reglas del juego. Antes auditaba cada artículo a mano; ahora la checklist vive en la memoria del modelo.

Con Encuora, el cambio de proyecto es cambio de cerebro: el contexto cambia con un clic.
| ✅ Para ti si... | ❌ NO es para ti si... |
|---|---|
| Usas IA a diario y llevas 2-3+ meses con ella | Usas IA puntualmente |
| Manejas multi-proyecto o multi-cliente | Solo haces preguntas aisladas |
| Has sentido la fricción de repetir contexto | La memoria nativa de tu IA te basta |
| Eres founder, consultor, director de operaciones o creador con sistema | Necesitas SaaS enterprise con SSO/SOC2 |
| Te molesta el lock-in de plataforma | Te da igual quedarte con una sola IA |
Si quieres el tutorial completo con capturas de pantalla, te lo explico aquí en detalle.
Beta abierta gratis durante toda la beta. Cuando salgamos de beta, habrá un plan de pago. Aún no está definido públicamente.
No. Tu memoria es tuya. No la usamos para entrenar nada ni la cedemos a terceros.
Aún no. Pendiente de que Google publique soporte oficial para MCP. Cuando lo hagan, Encuora funcionará en Gemini el primer día.
Tu memoria es exportable. No es lock-in: si dejamos de existir, te llevas tu grafo y puedes importarlo a cualquier herramienta compatible con MCP.
Sí, control total. Cualquier entidad, observación o relación es editable y borrable.
No. Projects es excelente si trabajas solo con Claude y tu contexto cabe en documentos estáticos. Encuora funciona cross-IA y consulta los hechos solo cuando son relevantes. La distinción técnica: «estructurada vs literal».
La memoria de ChatGPT vive dentro de OpenAI; Encuora vive en servidores propios y se conecta vía MCP. Si cambias de IA, tu memoria de ChatGPT se queda en OpenAI; tu memoria de Encuora viaja contigo.
Salva, Carlos y yo construimos Encuora porque vivíamos el problema cada día. No es la herramienta más sofisticada del mercado —no se ha lanzado al mercado siquiera, sigue en beta—. Pero ataca un problema real: la memoria de tu IA debería pertenecerte y debería viajar contigo.
Si llevas tiempo trabajando con IA y has sentido que cada conversación nueva empieza demasiado pronto, demasiado en blanco, este producto te puede ayudar.
Tu IA puede saber quién eres. Encuora hace que también recuerde lo que has hecho.
Estamos en beta abierta y gratuita. Apúntate en encuora.com y entrarás en la lista de espera.
