
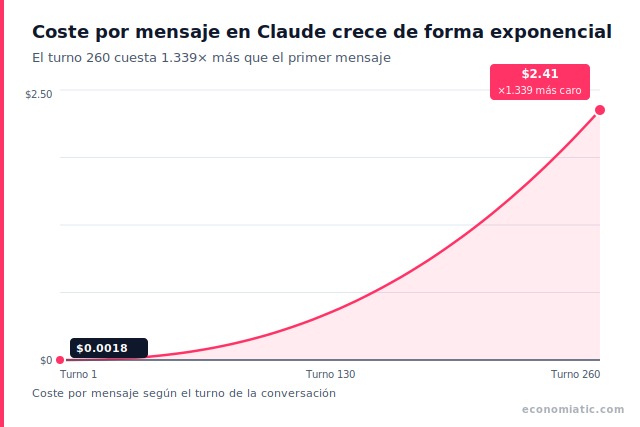
¿Por qué tus sesiones de Claude se agotan antes que hace tres meses? No es tu imaginación. Un desarrollador midió el mismo prompt de 14 tokens: en el turno 1 costó $0.0018, pero en el turno 260 de la misma conversación costó $2.41. Multiplicador de 1.339×.1
El problema no son los modelos más caros, es la arquitectura de cómo funciona Claude. En sesiones largas, la mayoría de los tokens que el modelo procesa NO son tu pregunta del momento. Son el contexto acumulado. En el análisis de Concessao, en el mensaje 206 de una sesión una pregunta de 1.581 tokens representaba solo el 1,3% del total procesado (~118K tokens).
Según datos de Plurality Network, los usuarios intensivos dedican más de 200 horas al año a reexplicar contexto a herramientas de IA.2 Eso son dos horas por semana que no producen nada.
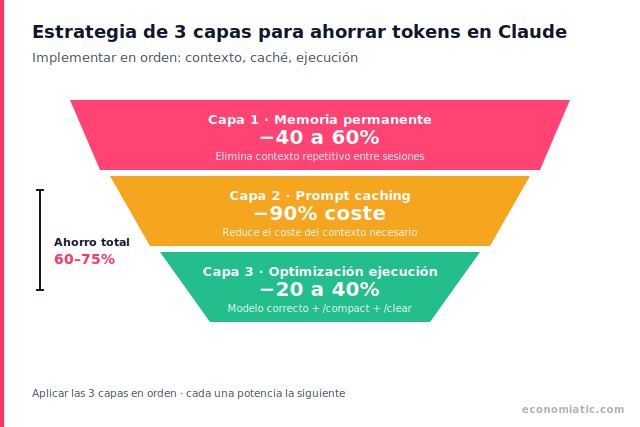
La solución existe, pero la mayoría la implementa al revés. Este artículo te muestra la estrategia de 3 capas para ahorrar tokens con Claude en el orden correcto: primero eliminas el contexto repetitivo, luego optimizas lo que queda, y finalmente ajustas la ejecución.
Conclusiones clave
- La memoria persistente elimina el contexto repetitivo que el modelo vuelve a procesar en cada sesión nueva. Es la optimización más efectiva porque ataca la causa raíz, no los síntomas.
- El prompt caching reduce hasta 90% el coste del contexto necesario (precios oficiales de Anthropic), pero solo funciona si antes has reducido el contexto base con memoria persistente.
- Las técnicas de prompting optimizan la ejecución, pero son la capa final: sin las dos anteriores, los ahorros son marginales.
Cada conversación con Claude funciona como una curva de coste exponencial. El primer mensaje cuesta centavos. El mensaje 260 cuesta más de mil veces lo que costó el primero, aunque tu pregunta tenga exactamente las mismas 14 palabras.
La razón es simple: Claude no tiene memoria nativa entre mensajes. Para "recordar" lo que dijiste tres turnos atrás, tiene que volver a procesar todo el historial acumulado.
Claude Code limita las sesiones no por cantidad de mensajes, sino por presupuesto de tokens consumidos en ventanas de 5 horas. Los usuarios piensan que les quedan 50 mensajes cuando en realidad el presupuesto ya está al 90%.
El mayor desperdicio de tokens no está en cómo haces las preguntas, está en repetir el contexto base una y otra vez.
Si usas múltiples entornos o IAs:
Crea cuenta en encuora.com
Configura tu "cerebro" con tu contexto: rol, proyectos, preferencias, stack
Conecta Claude (y ChatGPT si usas ambos)
Resultado: contexto cargado automáticamente en cada sesión nueva.
Si solo usas Claude web:
Crea un Project en claude.ai
Añade tu contexto base en las instrucciones del proyecto
Trabaja dentro de ese Project
Resultado: contexto compartido entre conversaciones del proyecto
Resultado: dejas de pagar el contexto que se repite en cada sesión nueva.
Si usas Claude Code o claude.ai: ya está activo automáticamente en conversaciones largas. Usa /context para ver cuánto está cacheado y /cost para ver el ahorro real.
Si usas la API:
Añade cache_control: {type: "ephemeral"} después de tu system prompt
Coloca breakpoints después de documentación estática
Cachea bloques de >1.024 tokens (Sonnet) o >4.096 (Haiku)
Resultado: el contexto que aún necesitas repetir entre mensajes pasa a costar 0.10× su precio base — datos oficiales de Anthropic.5

Elige el modelo correcto:
Haiku 4.5 ($0.25 input): Tareas simples, criterio claro (resumir, traducir, formatear)
Sonnet 4 ($3 input): Tareas intermedias, necesitas "correcto a la primera" (código, análisis)
Opus 4 ($15 input): Tareas críticas donde un error cuesta más que la diferencia de precio
Limpia el contexto regularmente:
En Claude Code: /compact cada 50 mensajes, /clear al cambiar de proyecto
Resultado: descartas el historial que ya no aporta y dejas de pagarlo en cada turno
Resultado: menos tokens malgastados en tareas que no los necesitan, y conversaciones que no acumulan contexto irrelevante.
La memoria persistente es un sistema externo al modelo que guarda información sobre ti entre sesiones distintas. No es una ventana de contexto más larga, es un mecanismo que carga tu contexto personal desde el primer mensaje de cada nueva conversación.

Si el 98,7% de tus tokens son contexto repetitivo, eliminar ese contexto ANTES de que el modelo lo procese es la optimización más efectiva. Optimizar prompts o activar caching sin reducir primero el contexto base es como intentar ahorrar gasolina limpiando el parabrisas.
Mejor contexto, no más contexto.
RECOMENDADO
| Solución | Alcance | Ventaja | Limitación |
|---|---|---|---|
| Encuora | Universal (Claude y ChatGPT) | Mismo contexto en todas las IAs | Requiere cuenta adicional |
| Projects (Claude) | Solo Claude, un entorno | Gratis, nativo, integrado | No cruza entre API/web/Code |
| ChatGPT Memory | Solo ChatGPT | Aprende automáticamente | Sin control granular |
Veredicto: Encuora si usas múltiples IAs o entornos. Projects si solo usas claude.ai. ChatGPT Memory solo si usas exclusivamente ChatGPT.
Sonnet 4: $3 input, $3.75 cache write, $0.30 cache read por millón de tokens.
Opus 4: $15 input, $18.75 cache write, $1.50 cache read por millón de tokens.3
Un bloque de 10.000 tokens en 10 mensajes: sin caching $30, con caching $6.45 — ahorro del 78,5%. En 50 mensajes, el ahorro sube al 92%.
Mínimo cacheable: 1.024 tokens para Sonnet, 4.096 para Haiku. Puedes tener hasta 4 breakpoints por prompt.4
| Estrategia | Ahorro real | Esfuerzo | Cuándo usarla |
|---|---|---|---|
| Memoria persistente (Encuora) | Sustancial — elimina contexto repetitivo | Una vez | Proyectos largo plazo, múltiples clientes |
| Prompt caching | 90% (solo hits) | Medio | Conversaciones largas con contexto repetido |
| Model switching | Hasta 60× diferencia Haiku/Opus | Bajo | Por tarea según complejidad |
| /compact • /clear | Variable según historial | Bajo | Sesiones >30 mensajes |
| Caveman Mode | 4-10% | Bajo | Output-heavy workflows |
Ejemplo real de Branch8 (equipo APAC): antes $13/dev/día, después $4/dev/día con estrategia completa. Ahorro: 70%.5
Los benchmarks reales:6
Veredicto: los ahorros provienen de combinar todas las capas, no de aplicar una sola.
Reducir el prompt de 100 a 50 tokens ahorra centavos. Reducir el contexto repetido de 10.000 a 4.000 tokens tiene dos órdenes de magnitud más impacto. Mide con /cost en Claude Code.
Projects no cruza entre claude.ai + Claude Code + API. Si usas múltiples entornos o varias IAs, Encuora ofrece memoria universal.
Implementa una técnica, mide 1 semana, compara con baseline. Regla de oro: si aporta <5% de ahorro y añade complejidad, elimínala.
Mínimo 1.024 tokens (Sonnet) o 4.096 (Haiku). Agrupa bloques pequeños en uno grande.
Implementa, mide 1 semana, compara con baseline. Si el ahorro real es <10% del claim, descarta la técnica.
💡 ¿Quieres que Claude recuerde sin repetir contexto cada vez?
Encuora conecta tu memoria persistente a Claude y ChatGPT simultáneamente. Configurada una vez, funciona en cada conversación nueva.
Beta abierta gratuita. 👉 encuora.com
Tu IA puede saber quién eres. Encuora hace que también recuerde lo que has hecho.
Los ahorros de Branch8 ($13→$4/dev/día) vienen de la estrategia integrada, no de técnicas aisladas. La memoria persistente es la base; sin ella, el resto son optimizaciones marginales.
Próximo paso: configura memoria persistente esta semana. Mide con /cost. Activa Encuora o Projects. Vuelve a medir en 7 días.
Los precios oficiales de Anthropic (abril 2026): Haiku 4.5 $0.25/$1.25 por millón de tokens, Sonnet 4 $3/$15, Opus 4 $15/$75. Un usuario intensivo paga entre $150-250/mes con Sonnet. El 90% de ese coste suele ser contexto repetitivo que puede eliminarse con memoria persistente.
Porque el coste crece exponencialmente: el mensaje 260 cuesta 1.339× más que el mensaje 1 con el mismo prompt. Claude Code limita por presupuesto de tokens en ventanas de 5 horas, no por cantidad de mensajes. Una sesión de 50 mensajes puede agotar el presupuesto si cada mensaje procesa mucho historial acumulado.
Un sistema que guarda información sobre ti entre sesiones distintas. En lugar de repetir tu contexto en cada chat nuevo, la memoria persistente lo carga automáticamente desde el primer mensaje. Dejas de pagar el contexto repetitivo cada sesión. Más detalle: qué es la memoria persistente para IA.
No. Claude Pro ($20/mes) tiene límites basados en compute que resetean en ventanas de 5 horas. No es un límite fijo de mensajes, es un presupuesto de tokens consumidos. Si tu uso es muy intensivo puedes alcanzar el límite incluso con Pro.
Primera vez: 1.25× el precio base (cache write). Siguientes: 0.10× = 90% de ahorro (cache read). Automático en Claude Code y claude.ai; con cache_control: {type: "ephemeral"} en la API. El cache expira a los 5 minutos. Mínimo cacheable: 1.024 tokens (Sonnet) o 4.096 (Haiku).
Haiku ($0.25 input) para tareas simples con criterio claro: resumir, traducir, formatear. Sonnet ($3) para comprensión de contexto y generación coherente: código, análisis, redacción. Opus ($15) cuando la calidad es tan crítica que rehacerlo costaría más que la diferencia de precio. Regla práctica: menos de 30 segundos de verificación → Haiku; correcto a la primera → Sonnet; error cuesta más de $20 → Opus.
Projects si solo usas claude.ai en un único entorno: es gratis y nativo. Encuora si usas múltiples entornos (claude.ai + Claude Code + API) o varias IAs (Claude + ChatGPT): ofrece memoria universal cross-platform con el mismo contexto disponible en todos los modelos compatibles.
Marketing inflado. Caveman Mode solo reduce el output un 15-25%, que representa menos del 10% del coste total. El caso Branch8 logró ahorros sustanciales combinando TODAS las técnicas: memoria persistente + prompt caching + model switching. Ningún ahorro del 75% proviene de una sola técnica.
Los precios y ahorros son estimaciones basadas en datos de abril 2026. Consulta la página oficial de Anthropic para información actualizada.
