
Tardas diez horas en publicar un artículo. Eso son diez horas de búsquedas, borradores, ajustes SEO, formateo en WordPress y subida de imágenes. Diez horas que se repiten cada vez que publicas.
La promesa de la IA era que ese tiempo desaparecería. Y en parte es verdad. Pero hay un matiz que casi nadie explica: usar IA sin método no resuelve el problema, solo lo desplaza. Crear contenido con IA de manera ad-hoc ahorra tiempo en la redacción, pero lo recuperas reexplicando contexto, repegando instrucciones y reconstruyendo el hilo en cada nueva sesión.
Este artículo no es una comparativa teórica. Es el resultado de medir fase a fase nuestro propio proceso en Economía TIC:
Los artículos que lees en este site se producen con ese pipeline de automatización editorial. Los datos de la tabla son los tiempos reales que registramos al producirlos.
En este artículo aprenderás:
- Qué es el overhead de contexto y por qué arruina las estimaciones de ahorro con IA
- La comparativa de las 3 formas de trabajar con tiempos reales por fase
- Los 5 pasos para hacer la transición desde cero
- Los errores más frecuentes al automatizar el proceso editorial
Los modelos de IA como Claude o ChatGPT no tienen memoria entre sesiones. Cada vez que abres una conversación nueva, el modelo empieza desde cero: no sabe quién eres, cuál es tu style guide, qué artículo estás escribiendo ni qué se decidió en la sesión anterior. Puedes leer la explicación técnica de por qué ocurre en por qué Claude no recuerda conversaciones.
El overhead de contexto es el tiempo que dedicas a reconstruir ese estado en cada sesión nueva:
- pegar el style guide
- explicar la estructura del artículo
- recordarle a la IA el tono de tu publicación
- repetirle las reglas de publicación en WordPress.
Es trabajo real, necesario para que la IA produzca algo útil, pero que no avanza el artículo ni un párrafo.
Los usuarios intensivos de IA dedican más de 200 horas al año a esta tarea de reexplicación.1 Con cuatro sesiones por artículo —research, redacción, SEO, publicación— son entre 60 y 90 minutos de overhead por artículo. Invisible en cualquier estimación optimista. Muy visible en la práctica.
Este coste oculto es la razón por la que el modelo de “IA sin sistema” ahorra tiempo en teoría pero decepciona en la práctica. Y es exactamente lo que resuelve la memoria persistente.
Esta es la tabla que falta en la mayoría de guías sobre IA editorial.
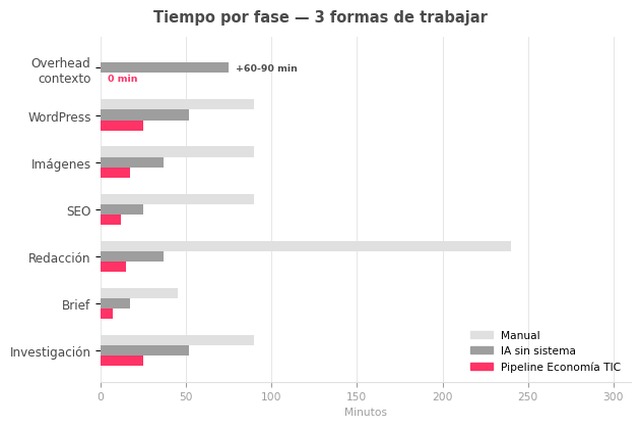
No “cuánto podrías ahorrar en teoría”, sino cuánto tarda cada fase en cada modelo de workflow para crear contenido con IA, medido en artículos reales de Economía TIC.
Los tiempos de la columna “manual” son los que medimos antes de implementar el pipeline. Los del pipeline corresponden a artículos producidos en abril de 2026:
| Fase | Manual | IA sin sistema | Pipeline Economía TIC |
|---|---|---|---|
| Investigación + fuentes | 1,5 h | 45–60 min | 20–30 min |
| Brief + outline | 30–60 min | 15–20 min | 5–10 min |
| Redacción (~2.000 palabras) | 3–5 h | 30–45 min | 10–20 min |
| SEO (KW, meta, enlaces) | 1–2 h | 20–30 min | 10–15 min |
| Imágenes | 1–2 h | 30–45 min | 15–20 min |
| Formateo WordPress + schema | 1–2 h | 45–60 min | 20–30 min |
| Overhead de contexto | — | 60–90 min | 0 min |
| Total | 8–13,5 h | 4–6 h | 75–115 min |
El modelo de “IA sin sistema” parece la solución obvia: usas Claude o ChatGPT para lo que puedes y haces el resto a mano. El problema es el overhead descrito arriba: cuatro sesiones por artículo, entre 15 y 22 minutos de setup cada una, son 60–90 minutos que no aparecen en ningún prompt pero que pagas igualmente en tiempo.
El salto real está en la memoria, no en la velocidad. La diferencia entre el segundo y el tercer modelo no es que la IA escriba más rápido. Es que el tercer modelo elimina el overhead por completo. La memoria persistente para IA hace que cada sesión arranque con todo el contexto cargado: style guide, instrucciones del pipeline, historial de decisiones, reglas de publicación. Sin reexplicar nada. Eso es lo que separa la generación de contenido automatizada de simplemente “usar ChatGPT para escribir”.
Nosotros lo hacemos con Encuora, una herramienta de memoria persistente diseñada para equipos que trabajan con múltiples modelos de IA:
Mejor contexto, no más contexto.
Nuestro pipeline editorial tiene siete skills en cadena:
content-strategistcontent-researcherarticle-writerseo-llm-optimizerproduct-placementblog-enricherblog-publisherCada skill opera con el contexto completo del proyecto cargado desde Encuora al inicio de cada sesión.
No hay fase de setup. Un orquestador llama a cada skill en orden, pasa el output como input de la siguiente y registra el progreso.
La publicación en WordPress queda integrada vía MCP,2 eliminando el formateo manual de Gutenberg.
Tiempo estimado para aplicar la metodología: 1 semana de transición
Requisitos previos:
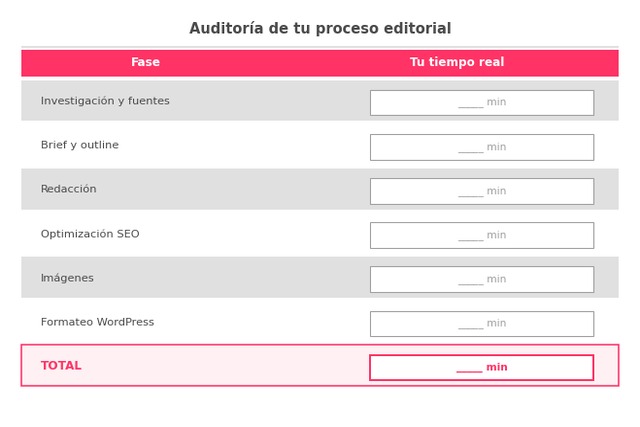
El primer error al automatizar un proceso es hacerlo sin medirlo. Coge un artículo real y cronometra cada una de las seis fases: investigación y fuentes, brief y outline, redacción, optimización SEO, imágenes y formateo en WordPress. Anota el tiempo sin estimaciones: cronómetro en mano, no memoria.
Una sola medición ya te da el baseline que necesitas. Aunque el tiempo total te sorprenda, conocerlo es la única forma de demostrar después que la automatización editorial funcionó y de convencer a tu equipo de hacer el cambio.
Clasifica cada una de las seis fases auditadas en una de estas tres categorías:
Delegable al 100%: investigación y síntesis de fuentes, redacción, SEO técnico (meta, densidad, schema), generación de imágenes, formateo WordPress vía API.
Revisión humana obligatoria: validación de datos y cifras, juicio editorial sobre el ángulo, publicación final.
La IA agiliza pero no elimina: brief y outline (la IA propone, tú decides), internal linking (la IA sugiere, tú verificas).
La regla: si la tarea tiene un output verificable y reproducible, la IA puede ejecutarla. Si requiere criterio editorial, la IA asiste. Esta distinción es la base de cualquier workflow de contenidos con IA que funcione a largo plazo.
Con los datos de la comparativa de arriba, elige el modelo que encaja con tu situación actual:
Empiezas desde cero: configura el pipeline básico del Paso 4 y valida el flujo con un artículo real antes de añadir capas.
Ya usas IA ad-hoc pero el overhead te frena: pasa directamente al modelo completo con memoria persistente (Paso 5). El cuello de botella no está en las herramientas, está en el contexto.
Tienes equipo editorial: el modelo completo con Encuora es el único que escala, porque el contexto se comparte entre sesiones y personas.
No hay un modelo universalmente correcto. Hay el que resuelve el cuello de botella que tienes ahora.
El pipeline básico tiene cuatro herramientas IA para crear artículos en cadena:
content researcher (brief con fuentes y ángulo diferenciador)
article writer (borrador completo desde el brief y el style guide)
SEO optimizer (meta description, densidad de keyword, schema JSON-LD)
blog publisher (formateo en WordPress).
El tiempo activo humano en cada una es de 10–20 minutos: revisar el output, aprobar o ajustar, pasar a la siguiente.
El cuello de botella de este modelo es la publicación: sin integración vía MCP, el formateo manual en Gutenberg sigue consumiendo 45–60 minutos. Ese es el problema que resuelve el paso siguiente.
La configuración tiene tres acciones:
Crear la base de conocimiento editorial. Documenta en Encuora (o el sistema que elijas): style guide completo, pipeline fase a fase, reglas de publicación WordPress, keywords y categorías del site. Setup único; no se vuelve a tocar salvo actualizaciones deliberadas.
Integrar WordPress vía MCP. Conecta tu instalación de WordPress con el modelo de IA mediante Application Password (wp-admin → ajustes → contraseñas de aplicación) y configura el servidor MCP. Una vez activo, la IA crea y actualiza posts directamente, sin intermediarios.
Definir el protocolo de sesión. Inicio: cargar contexto desde la memoria. Cierre: registrar las decisiones relevantes. Ese bucle de dos acciones es lo que hace que el sistema mejore con cada artículo en lugar de resetear.
Herramientas:
RECOMENDADO
A nosotros tampoco. Por eso usamos Encuora — la herramienta que hace que tu IA arranque cada sesión con todo el contexto cargado.
Conclusiones clave
- En Economía TIC, un artículo manual tardaba entre 8 y 13 horas. La mayor parte del tiempo no estaba en escribir: estaba en investigar, formatear y publicar.
- Usar IA de forma ad-hoc redujo el tiempo a 4–6 horas, pero introdujo un overhead de contexto de 60–90 minutos por artículo que las estimaciones optimistas ignoran.
- Con el pipeline completo —skills especializadas, integración WordPress vía MCP y memoria persistente con Encuora— el tiempo activo por artículo bajó a 75–115 minutos. No porque la IA sea más rápida, sino porque el contexto persiste, el flujo está orquestado y la publicación está automatizada. El resultado es un salto real en productividad editorial, no solo en velocidad de redacción.
- El punto de entrada más eficiente es el style guide: un documento bien escrito multiplica la calidad de cualquier output de IA, con o sin memoria persistente.
Próximo paso: si quieres reducir el coste de tokens mientras implementas este pipeline de content marketing con IA, lee cómo ahorrar tokens con Claude: estrategia de 3 capas. Las dos optimizaciones son complementarias: una reduce tiempo, la otra reduce coste.
Si tu respuesta es “se lo tengo que recordar en cada sesión”, el problema no está en el modelo que usas. Está en que no tiene memoria de lo que ya le has enseñado.
Encuora — memoria persistente para tu pipeline editorial:
Tu IA puede saber quién eres. Encuora hace que también recuerde lo que has hecho.
La configuración inicial lleva entre 4 y 8 horas, repartidas principalmente en escribir el style guide y documentar las reglas del pipeline. A partir del segundo artículo, ese coste está amortizado y el tiempo por artículo cae a los 75–115 minutos del modelo completo.
Cualquier sistema que permita cargar contexto persistente entre sesiones funciona en principio. La diferencia específica de Encuora está en la integración directa con el pipeline editorial y la capacidad de registrar decisiones de forma estructurada. Un documento de contexto pegado al inicio de cada sesión ya elimina buena parte del overhead, aunque no lo automatiza.
Sí, vía MCP (Model Context Protocol), el estándar abierto de Anthropic para integrar modelos de IA con herramientas externas. La IA puede crear borradores, insertar bloques de Rank Math, subir imágenes y configurar campos SEO. La intervención humana queda para la revisión final y la aprobación de publicación; no para el formateo técnico.
Con un style guide bien definido y revisión humana de datos y claims, la calidad se mantiene o mejora. La IA es especialmente buena en coherencia estructural y densidad de keyword; el editor humano aporta criterio editorial y verificación de hechos. El pipeline no reemplaza el juicio editorial, lo libera para que se aplique donde importa.
Funciona bien para artículos informativos, guías, comparativas y diccionario. Es especialmente efectivo para blogs de inteligencia artificial con cadencia regular de publicación, donde el contexto acumulado entre artículos genera valor compuesto. Funciona peor para contenido que requiere experiencia personal verificable (reviews con uso real) o investigación primaria.
El coste principal es el modelo de IA (Claude Sonnet cuesta aproximadamente $3 por millón de tokens de entrada). Un artículo de 2.000 palabras con el pipeline completo consume entre $0,15 y $0,40 en tokens. El coste de memoria persistente depende de la herramienta; Encuora está en beta con acceso gratuito en lista de espera.
Sí. El pipeline básico (investigación, redacción, SEO) funciona completamente sin integración WordPress. El resultado es un documento formateado que copias y pegas manualmente. Pierdes el ahorro de la fase de publicación (20–30 min del modelo completo), pero el resto del ahorro se mantiene.
