
Cada vez que una app de streaming acierta con la serie que te apetecía, que tu banco frena un cargo fraudulento en segundos o que un hospital prioriza a un paciente de riesgo, hay una misma disciplina trabajando por debajo.
Saber qué es la ciencia de datos (data science) ayuda a entender cómo se toman hoy muchas de las decisiones que nos afectan, y por qué este perfil profesional aparece en casi todas las listas de empleos más demandados.
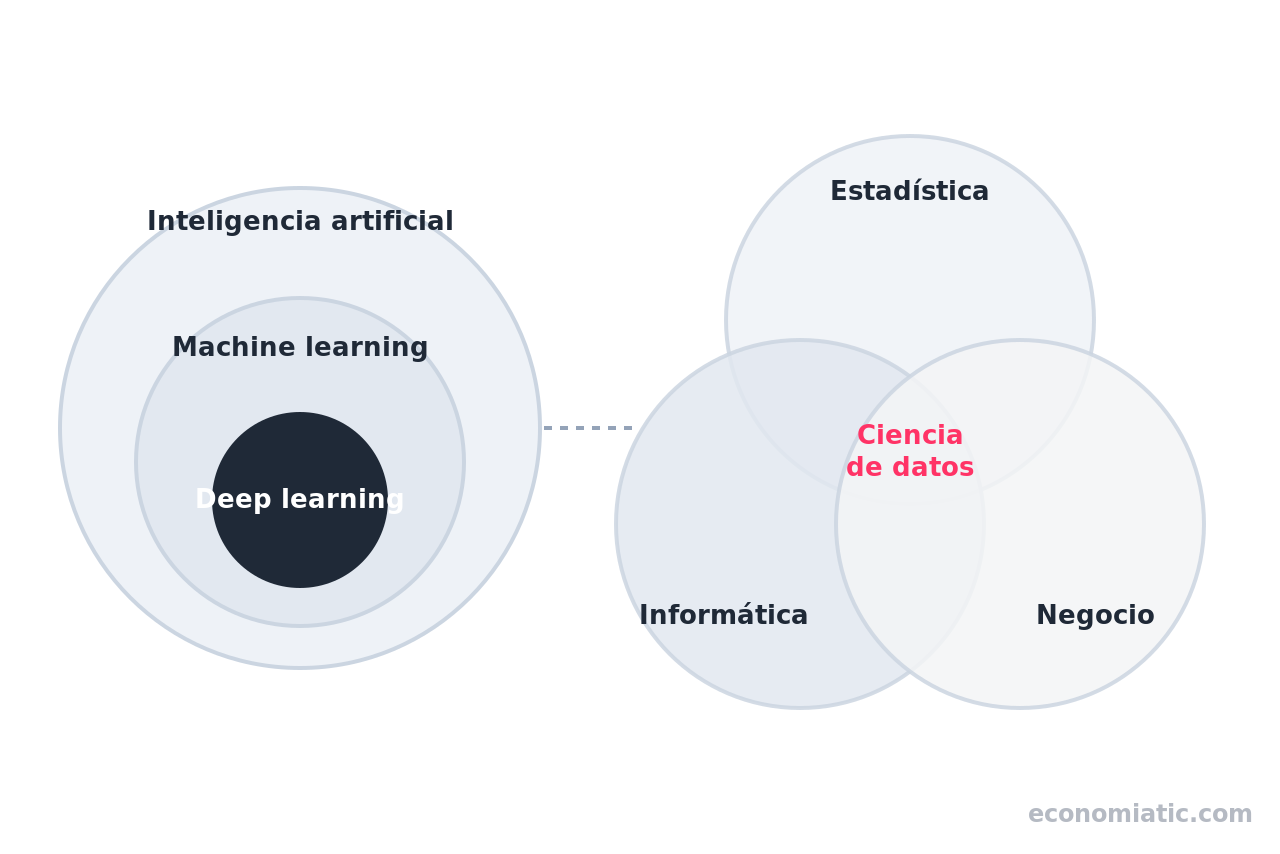
El problema es que el término llega rodeado de otros que parecen sinónimos —big data, machine learning, inteligencia artificial, estadística— y rara vez alguien se molesta en separarlos con claridad.
Lo importante
- La ciencia de datos es la disciplina que combina estadística, programación y conocimiento de negocio para convertir datos en decisiones; abarca todo el ciclo del dato, de la obtención a la comunicación de resultados.
- No es lo mismo que big data, machine learning ni inteligencia artificial: el big data son los datos, el machine learning es una de sus herramientas y la IA es el campo más amplio que la rodea.
- El empleo de científicos de datos está entre los de mayor crecimiento (el BLS de EE. UU. proyecta un 34% entre 2024 y 2034) y en España figura entre los perfiles tecnológicos más demandados.
Este artículo hace justo eso: define el concepto sin jerga, lo distingue de las disciplinas que se le confunden, explica cómo trabaja un equipo de datos con una metodología reconocida y aterriza qué significa todo esto en el mercado laboral español.
Sin hype ni alarmismo.
La ciencia de datos (data science) es la disciplina que combina estadística, programación y conocimiento de negocio para extraer información útil de los datos y convertirla en decisiones.
Abarca todo el ciclo del dato: desde su obtención y limpieza hasta el análisis, el modelado predictivo y la comunicación de resultados a quien tiene que actuar.
La palabra clave de esa definición es decisiones.
La ciencia de datos no consiste en acumular información ni en construir el modelo más sofisticado posible, sino en responder preguntas concretas con evidencia: ¿qué clientes van a marcharse?, ¿cuánto stock necesito el mes que viene?, ¿qué transacción es sospechosa?
Por eso se la describe como una disciplina interdisciplinar12: requiere las matemáticas de la estadística, la capacidad de la informática para procesar datos a escala y el criterio de negocio para saber qué pregunta merece la pena responder.
Si los datos fueran ingredientes de una cocina, el big data sería la despensa enorme y un poco desordenada, la ciencia de datos sería el chef y su método de trabajo, el machine learning sería un robot de cocina que el chef usa cuando le conviene, y la inteligencia artificial sería todo el arte culinario que engloba a los demás.
Es una analogía imperfecta, pero ordena de golpe cinco términos que casi nadie separa bien.
El término tiene más recorrido del que parece. Ya en 1962 el estadístico John W. Tukey reclamaba en The Future of Data Analysis una ciencia del análisis de datos que fuera más allá de la estadística matemática clásica3.
La etiqueta moderna se asienta en 2001, cuando William S. Cleveland propuso en Data Science ampliar formalmente el campo de la estadística hacia la computación con datos4. Y la disciplina entró en la conversación de los negocios en 2012, cuando Thomas Davenport y D. J. Patil publicaron en Harvard Business Review el célebre artículo que calificaba al científico de datos como «el trabajo más sexy del siglo XXI»5.
No es, por tanto, una moda surgida con la IA generativa: es la maduración de una idea con sesenta años de historia.
La diferencia entre estas disciplinas es de naturaleza, no de grado: el big data describe los datos, la ciencia de datos describe el método, el machine learning es una técnica concreta y la inteligencia artificial es el campo que las engloba en parte. Confundirlas es el malentendido más extendido sobre el tema, así que conviene desmontarlo término a término.
| Concepto | Qué es | Foco | Ejemplo |
|---|---|---|---|
| Big data | Grandes volúmenes de datos variados y a alta velocidad | Los datos en sí | El historial completo de clics de millones de usuarios |
| Ciencia de datos | Disciplina que extrae conocimiento de los datos | El método y todo el ciclo del dato | Un sistema que predice qué clientes se darán de baja |
| Machine learning | Técnica para que un modelo aprenda patrones | El algoritmo que aprende y predice | El motor que recomienda productos |
| Estadística | Ciencia de inferir y cuantificar la incertidumbre | El rigor del razonamiento con datos | Saber si una diferencia es significativa o azar |
| Inteligencia artificial | Campo que busca sistemas con capacidades inteligentes | Replicar tareas cognitivas | Un asistente conversacional |
El big data son los datos; la ciencia de datos es lo que se hace con ellos.
El primero describe conjuntos de información tan grandes, variados y veloces que las herramientas tradicionales no los manejan bien —la materia prima—. La segunda es la disciplina que los interroga para sacar conclusiones.
Puede haber ciencia de datos sin big data (con una hoja de cálculo bien analizada ya estás haciendo análisis riguroso) y puede haber big data sin ciencia de datos (terabytes almacenados que nadie aprovecha). Se necesitan, pero no son lo mismo.
El machine learning (aprendizaje automático) es una de las herramientas que usa la ciencia de datos, no su sustituto.
Consiste en algoritmos que aprenden patrones a partir de datos históricos para hacer predicciones sin estar programados explícitamente para cada caso.
Es potentísimo, pero es solo una de las fases posibles: un proyecto de ciencia de datos también puede resolverse con estadística clásica, con una visualización bien hecha o con una consulta SQL inteligente.
El machine learning entra cuando la pregunta requiere predecir, clasificar o agrupar a escala.
La inteligencia artificial (IA) es el campo más amplio que persigue construir sistemas capaces de tareas que asociamos a la inteligencia humana: percibir, razonar, decidir, comunicarse.
La ciencia de datos y la IA se solapan —el machine learning pertenece a ambas— pero no coinciden. La ciencia de datos persigue entender y decidir a partir de datos; la IA persigue automatizar capacidades cognitivas.
Un análisis que explica por qué cayeron las ventas es ciencia de datos pura y no necesariamente IA; un chatbot es IA y no necesariamente un proyecto de análisis.
La estadística es el corazón matemático de la ciencia de datos, pero esta añade dos cosas que la estadística clásica no incluía: la computación a gran escala y la orientación a producto.
Cleveland lo dejó escrito en 2001, al pedir que la estadística incorporase formalmente la computación con datos.
El análisis de datos (data analytics), por su parte, suele referirse a explorar lo que ya ocurrió —informes, paneles, métricas—, mientras que la ciencia de datos suele ir un paso más allá, hacia lo predictivo y lo prescriptivo: no solo qué pasó, sino qué pasará y qué conviene hacer.
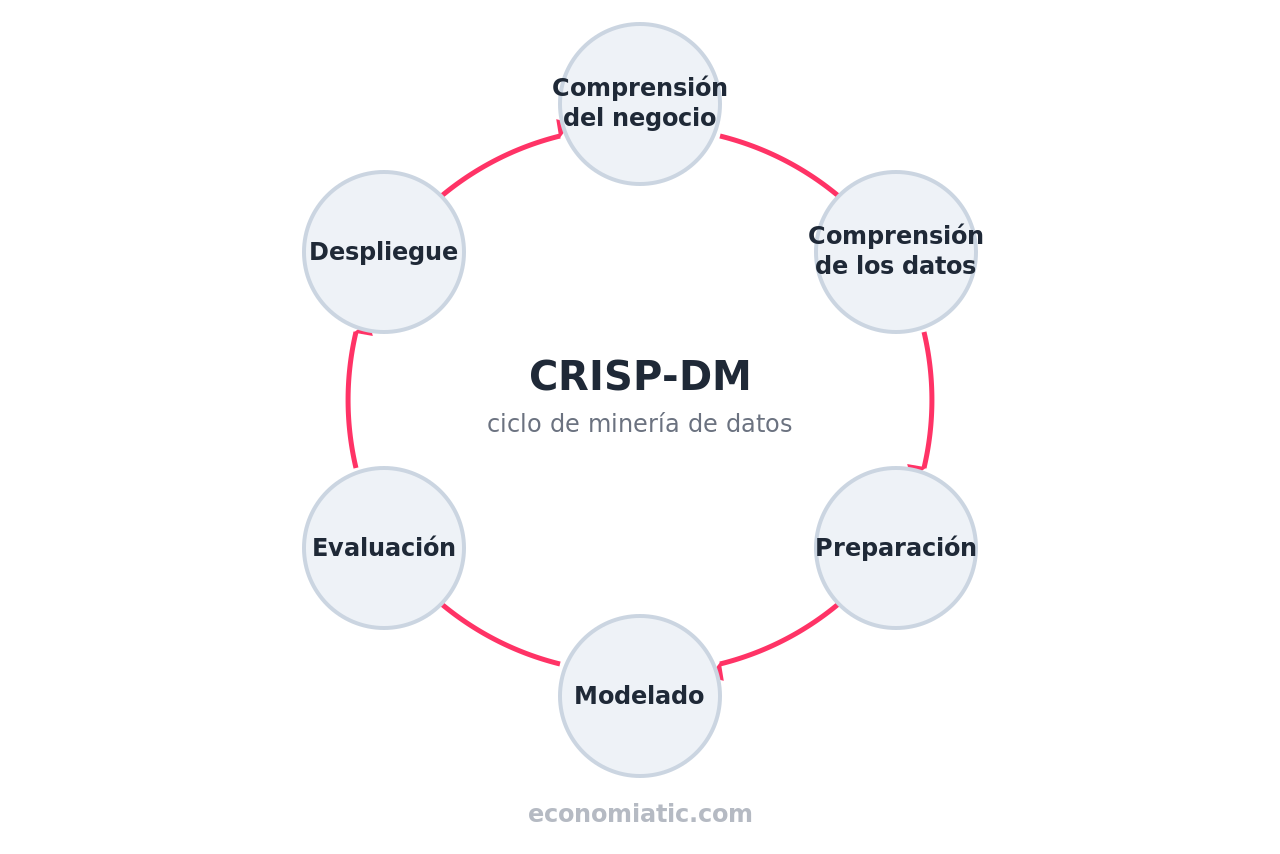
El trabajo de la ciencia de datos sigue un ciclo de fases encadenadas que va del problema de negocio a la decisión, y la metodología más reconocida para describirlo es CRISP-DM (Cross-Industry Standard Process for Data Mining), un estándar abierto creado en los años noventa que define seis fases67.
Lejos de ser una lista lineal, sus etapas se realimentan: es habitual volver atrás cuando los datos revelan algo que cambia el planteamiento inicial.
Existe una metodología alternativa más sintética, OSEMN (Obtain, Scrub, Explore, Model, iNterpret), popular en entornos académicos.
La lección de fondo es común: la ciencia de datos es un proceso ordenado y cíclico, no un acto de magia con un algoritmo.
Un científico de datos (data scientist) es el profesional que ejecuta ese ciclo:
Su valor está en la combinación poco común de cuatro competencias:
De esa rareza venía, en parte, la etiqueta de «trabajo más sexy del siglo XXI» de Davenport y Patil.
Conviene matizar el cliché. El día a día tiene menos de modelado espectacular y más de fontanería de datos: entender de dónde sale cada cifra, depurar inconsistencias y discutir con negocio qué se quiere medir.
El científico de datos convive con perfiles vecinos —el analista de datos, más centrado en informes; el ingeniero de datos, que construye las tuberías que alimentan todo; y el ingeniero de machine learning, que industrializa los modelos—, y en equipos pequeños una sola persona asume varios de esos roles.
Las herramientas se agrupan en bloques bastante estables. En lenguajes de programación, Python domina con claridad el sector —es el más usado entre profesionales de datos según encuestas del propio ecosistema— acompañado de R para análisis estadístico y de SQL para consultar bases de datos, una destreza imprescindible que a menudo se subestima8.
Sobre Python se apoyan librerías como pandas, scikit-learn o las de visualización.
Para comunicar resultados, herramientas de business intelligence como Power BI o Tableau.
Y para trabajar a escala, plataformas en la nube (Azure, AWS, Google Cloud).
Por encima del instrumental, lo que distingue a un buen científico de datos es el criterio: saber qué pregunta importa y cuándo un resultado es fiable.
La ciencia de datos se aplica en prácticamente cualquier sector que genere datos, que hoy son casi todos. Estos son los usos más consolidados.
El empleo en ciencia de datos crece con fuerza y figura entre los perfiles tecnológicos más demandados, también en España.
La referencia internacional con fuente primaria más sólida es la Oficina de Estadísticas Laborales de EE. UU. (BLS), que proyecta un crecimiento del empleo de científicos de datos del 34 % entre 2024 y 2034, «mucho más rápido que la media», con unas 23.400 vacantes anuales de media en la década9.
Esta cifra es estadounidense y no extrapolable sin matices, pero marca una tendencia clara. En el mercado de plataformas que sostiene la disciplina, Grand View Research estima un salto de unos 96.250 millones de dólares en 2023 a unos 470.920 millones en 2030, con un crecimiento anual compuesto del 26 %10.
En España, big data y ciencia de datos aparecen de forma recurrente entre los tres perfiles tecnológicos más buscados, junto a la IA/ML y la ciberseguridad11.
En cuanto a salarios, los rangos de mercado para 2025–2026 (agregados de varias fuentes del sector, orientativos) se mueven así:
| Nivel | Rango orientativo (bruto/año) |
|---|---|
| Junior (0–2 años) | 26.000–34.000 € |
| Mid (3–5 años) | 38.000–55.000 € |
| Senior (5+ años) | 60.000 € en adelante |
Madrid y Barcelona suelen pagar entre un 15 % y un 20 % por encima de la media nacional1213. Para formarse hay tres vías principales: grados y másteres universitarios en ciencia de datos, bootcamps intensivos y autoformación con recursos abiertos. La base recomendable es común: estadística, programación (Python y SQL) y un dominio de aplicación.
No hace falta ser científico de datos para que la disciplina te afecte. Si trabajas en una pyme, entender qué se puede —y qué no se puede— pedir a tus datos te ayuda a tomar mejores decisiones sin contratar a un equipo entero: una buena hoja de cálculo y las preguntas correctas ya son análisis.
Como ciudadano, muchas decisiones que te afectan —un precio, una recomendación, la aprobación de un crédito— salen de modelos de datos, y conocer su lógica te permite pedir explicaciones y detectar cuando algo no cuadra.
La alfabetización en datos se está volviendo una competencia básica.
La ciencia de datos no es un sinónimo elegante de big data ni una rama de la inteligencia artificial: es la disciplina que pone método donde hay datos, para que una organización decida con evidencia en lugar de con intuición.
Entender esa diferencia —y el ciclo ordenado que va de la pregunta de negocio a la decisión— es lo que separa el ruido del conocimiento útil.
En un entorno donde casi todo deja rastro de datos, saber qué se les puede pedir se ha convertido en una alfabetización básica, trabajes o no con ellos directamente.
Es la disciplina que convierte datos en decisiones combinando estadística, programación y conocimiento del negocio. En lugar de adivinar, una organización la usa para responder preguntas concretas con evidencia: qué venderá, qué cliente se va a marchar o qué operación es sospechosa. Cubre todo el camino, desde recoger y limpiar los datos hasta explicar la conclusión a quien debe actuar.
El big data son los datos; la ciencia de datos es el método que los convierte en conocimiento. El big data describe conjuntos de información enormes, variados y veloces. La ciencia de datos es la disciplina que los interroga para extraer conclusiones. Puede haber una sin la otra: datos masivos que nadie aprovecha, o análisis riguroso sobre conjuntos pequeños.
No: el machine learning es una de sus herramientas y la inteligencia artificial es el campo más amplio que la rodea en parte. La ciencia de datos busca entender y decidir a partir de datos; la IA busca automatizar capacidades cognitivas. El machine learning, que pertenece a ambas, es solo una de las técnicas que se usan cuando la pregunta requiere predecir o clasificar a escala.
Las seis fases del estándar CRISP-DM: comprensión del negocio, comprensión de los datos, preparación, modelado, evaluación y despliegue. No es una lista lineal, sino un ciclo que se realimenta: es normal volver a una fase anterior cuando los datos revelan algo nuevo. La preparación y limpieza de datos suele llevarse la mayor parte del tiempo del proyecto.
Los rangos orientativos de mercado para 2025–2026 van de 26.000–34.000 € en perfiles junior a más de 60.000 € en seniors, con Madrid y Barcelona un 15–20 % por encima de la media. Las cifras varían según la fuente, el sector y el tamaño de empresa, por lo que conviene tomarlas como orientación y no como dato cerrado.
