
Cada vez que tu banco bloquea un cargo sospechoso, tu móvil reconoce tu cara o un traductor convierte un párrafo entero en otro idioma, hay una red neuronal trabajando por debajo.
El término aparece en cada noticia sobre inteligencia artificial, casi siempre acompañado de la frase «funciona como el cerebro humano». Pero ¿qué es exactamente una red neuronal, cómo «aprende» y hasta qué punto se parece de verdad a un cerebro?
Lo importante
- Una red neuronal artificial es un modelo de IA inspirado en el cerebro que organiza unidades de cálculo —neuronas— en capas conectadas por pesos, y aprende ajustando esos pesos a partir de ejemplos.
- No "piensa" ni "entiende": detecta patrones minimizando el error entre lo que predice y la respuesta correcta. La analogía con el cerebro es su origen histórico, no una descripción literal.
- Es la técnica que hay detrás del reconocimiento facial, la detección de fraude, los traductores y la IA generativa; cuando tiene muchas capas, hablamos de deep learning.
Este artículo responde a esas tres preguntas en ese orden —qué es, cómo funciona y para qué sirve— sin fórmulas ni jerga innecesaria. Y con una promesa: vamos a ser honestos con la metáfora cerebral, que casi todos los glosarios sobrevenden.
Una red neuronal artificial es un modelo de inteligencia artificial inspirado en el cerebro humano: organiza unidades de cálculo —llamadas neuronas— en capas conectadas por pesos numéricos.
Aprende ajustando esos pesos a partir de ejemplos, hasta detectar patrones en datos como imágenes, texto o sonido sin que nadie programe reglas explícitas.
Esa es la definición corta. La idea de fondo es sencilla y vale la pena fijarla antes de entrar en detalle: en lugar de escribir a mano las reglas para resolver un problema —«si el píxel de arriba a la izquierda es oscuro, entonces…»—, le mostramos a la red miles de ejemplos resueltos y dejamos que ella misma encuentre las regularidades.
El programador no dicta las reglas; diseña una estructura capaz de descubrirlas.
A lo largo del artículo usaremos un mismo ejemplo para que todo encaje: reconocer un dígito escrito a mano, del 0 al 9.
Es el «hola mundo» de las redes neuronales y permite seguir el mecanismo de principio a fin sin perderse.
El nombre viene de la biología, pero conviene cogerlo con pinzas.
La inspiración fue real: una neurona artificial imita, de forma muy esquemática, cómo una neurona biológica recibe señales de otras, las combina y, si superan cierto umbral, «dispara» una señal a las siguientes. De ahí el vocabulario: neuronas, conexiones, activación.
Ahí termina el parecido. Una neurona artificial es una función matemática —una suma de números multiplicados por otros números—, no una célula viva.
El cerebro humano tiene unos 86.000 millones de neuronas conectadas de formas que aún no entendemos del todo, consume la energía de una bombilla y aprende de un puñado de ejemplos.
Una red neuronal necesita miles o millones de ejemplos y, en los modelos punteros, centros de datos enteros para entrenarse.
Una red neuronal no piensa ni entiende. Calcula. La metáfora cerebral explica de dónde salió la idea en 1943, no lo que hace el sistema hoy. Tenerlo claro evita dos errores habituales: creer que la IA «razona como nosotros» y, en el extremo opuesto, asustarse pensando que estamos creando cerebros artificiales. Ni una cosa ni la otra.
Una red neuronal funciona transformando unos datos de entrada en una respuesta de salida a través de capas sucesivas de neuronas. Cada neurona:
Repitiendo eso en muchas capas, la red convierte píxeles en bruto en una decisión: «esto es un 7».
Desglosemos las piezas una a una con nuestro dígito manuscrito.
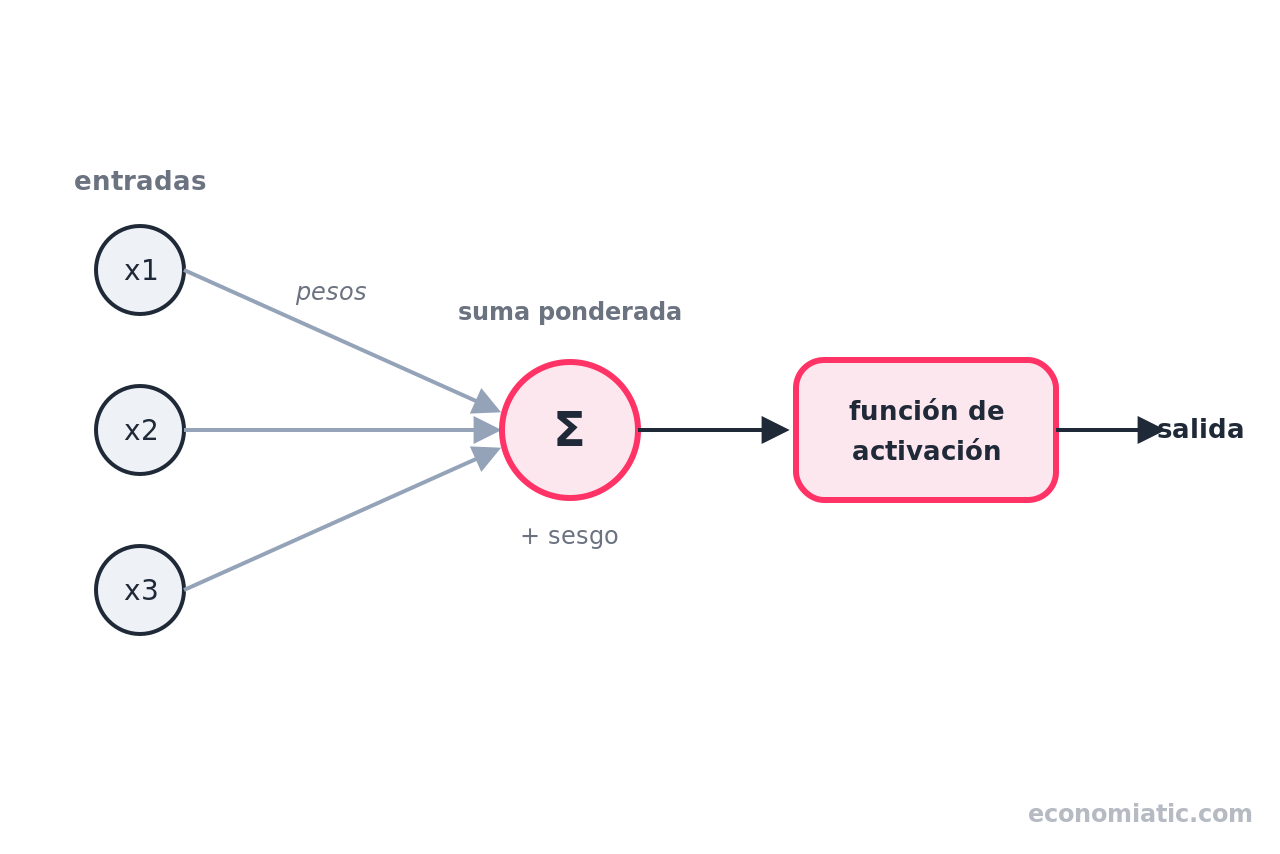
Una neurona artificial es la unidad básica de cálculo de la red: recibe varias entradas numéricas, multiplica cada una por un peso, suma el resultado, le añade un sesgo y produce un único número de salida. Pesos y sesgo son los valores que la red irá ajustando para aprender.
Imagina la imagen de nuestro dígito como una cuadrícula de 28×28 píxeles: 784 casillas, cada una con un número entre 0 (blanco) y 1 (negro). Esos 784 números son las entradas de la red.
Cada conexión entre neuronas tiene un peso (en inglés, weight): un número que dice cuánta importancia tiene esa entrada. Un peso alto amplifica la señal; uno cercano a cero la ignora; uno negativo la resta.
El sesgo (bias) es un ajuste extra que desplaza el resultado hacia arriba o hacia abajo.
La neurona hace una suma ponderada: multiplica cada entrada por su peso, lo suma todo y añade el sesgo. Un número entra, un número sale.
La función de activación es una operación que se aplica a la salida de cada neurona para decidir cuánta señal deja pasar a la siguiente capa, introduciendo un comportamiento no lineal. Sin ella, encadenar capas no serviría de nada: la red entera se comportaría como una simple recta.
Aquí está la clave que muchos textos se saltan. Si las neuronas solo sumaran y multiplicaran, apilar cien capas daría exactamente el mismo resultado que una sola: pura aritmética lineal.
La función de activación rompe esa linealidad. La más usada hoy, ReLU (Rectified Linear Unit), es brutalmente simple: si el número es negativo lo convierte en cero; si es positivo lo deja pasar tal cual. Ese pequeño «filtro» repetido millones de veces es lo que permite a la red aprender patrones complejos —curvas, esquinas, trazos— y no solo relaciones de línea recta.
Una red neuronal se organiza en tres tipos de capas: la capa de entrada recibe los datos en bruto, una o varias capas ocultas los transforman paso a paso, y la capa de salida produce el resultado final. Cada capa alimenta a la siguiente, refinando la información en cada paso.
En nuestro ejemplo:
Cuando una red tiene muchas capas ocultas —no dos o tres, sino decenas o cientos—, hablamos de redes profundas, y la disciplina que las entrena es el deep learning o aprendizaje profundo. La profundidad es, literalmente, el número de capas.
El entrenamiento es el proceso por el que la red ajusta sus pesos y sesgos comparando sus predicciones con las respuestas correctas y corrigiendo el error poco a poco. El algoritmo que reparte ese error hacia atrás por todas las capas se llama retropropagación (en inglés, backpropagation).
Al principio, los pesos son aleatorios: la red es como un estudiante que adivina a ciegas. Le mostramos una imagen de un «3» y, con sus pesos al azar, quizá responda «es un 8». Está equivocada.
Aquí entra el proceso de aprendizaje, que tiene tres movimientos que se repiten millones de veces:
Repite, repite, repite. Con cada ejemplo, los pesos se afinan y el error baja.
La analogía útil: bajar una montaña en la niebla dando pasos pequeños siempre cuesta abajo, hasta llegar al valle (el error mínimo).
Su popularización en 1986 por Rumelhart, Hinton y Williams fue lo que destrabó el entrenamiento de redes con muchas capas.
Las redes neuronales no son una moda reciente. Su recorrido —con dos «inviernos» de desilusión por medio— ayuda a entender por qué, de repente, están en todas partes.
En 1943, el neurofisiólogo Warren McCulloch y el lógico Walter Pitts publicaron el primer modelo matemático de una neurona artificial, capaz de realizar operaciones lógicas básicas2.
No había ordenadores para ejecutarlo; era pura teoría. Pero plantó la semilla: el comportamiento de una red de neuronas podía describirse con matemáticas.
En 1957-1958, Frank Rosenblatt llevó la idea más lejos con el perceptrón, la primera red entrenable de una sola capa, capaz de aprender los pesos por sí misma.
El entusiasmo fue enorme. Demasiado: en 1969, Marvin Minsky y Seymour Papert demostraron que un perceptrón de una capa no podía resolver problemas tan simples como la operación lógica XOR.
La financiación se evaporó y llegó el primer «invierno de la IA».
El problema del perceptrón se resolvía añadiendo capas ocultas, pero faltaba una forma práctica de entrenarlas. La retropropagación, popularizada en 1986, fue esa pieza.
Aun así, las redes seguían siendo lentas y hambrientas de datos para el hardware de la época.
El despegue real llegó alrededor de 2010, cuando coincidieron tres factores: cantidades masivas de datos (internet), GPU capaces de hacer millones de operaciones en paralelo, y mejores técnicas de entrenamiento.
En 2012, una red convolucional llamada AlexNet arrasó en un concurso de reconocimiento de imágenes y marcó el inicio de la era del deep learning. Las redes neuronales habían vuelto, esta vez para quedarse.
En 2024, la Real Academia Sueca de Ciencias concedió el Premio Nobel de Física a John J. Hopfield y Geoffrey Hinton «por descubrimientos e invenciones fundamentales que permiten el aprendizaje automático con redes neuronales artificiales»3.
Hopfield creó en los años 80 una memoria asociativa —la red de Hopfield— capaz de almacenar y reconstruir patrones usando conceptos de la física de los materiales. Hinton, partiendo de ese trabajo, desarrolló la máquina de Boltzmann con herramientas de física estadística.
Que un premio de Física reconozca trabajos sobre redes neuronales dice mucho: estas técnicas no nacieron en la informática pura, sino en el cruce entre biología, lógica y física. Es la consagración oficial de medio siglo de investigación.
No todas las redes neuronales son iguales. Su arquitectura —cómo se conectan las capas— se adapta al tipo de dato. Estas son las tres familias que más se nombran.
| Tipo | Para qué tipo de dato | Ejemplo de uso |
|---|---|---|
| Red neuronal convolucional (CNN) | Imágenes y vídeo | Reconocimiento facial, diagnóstico por imagen |
| Red neuronal recurrente (RNN) | Datos secuenciales (texto, audio, series temporales) | Reconocimiento de voz, predicción de series |
| Transformer | Secuencias largas (texto sobre todo) | ChatGPT y la IA generativa |
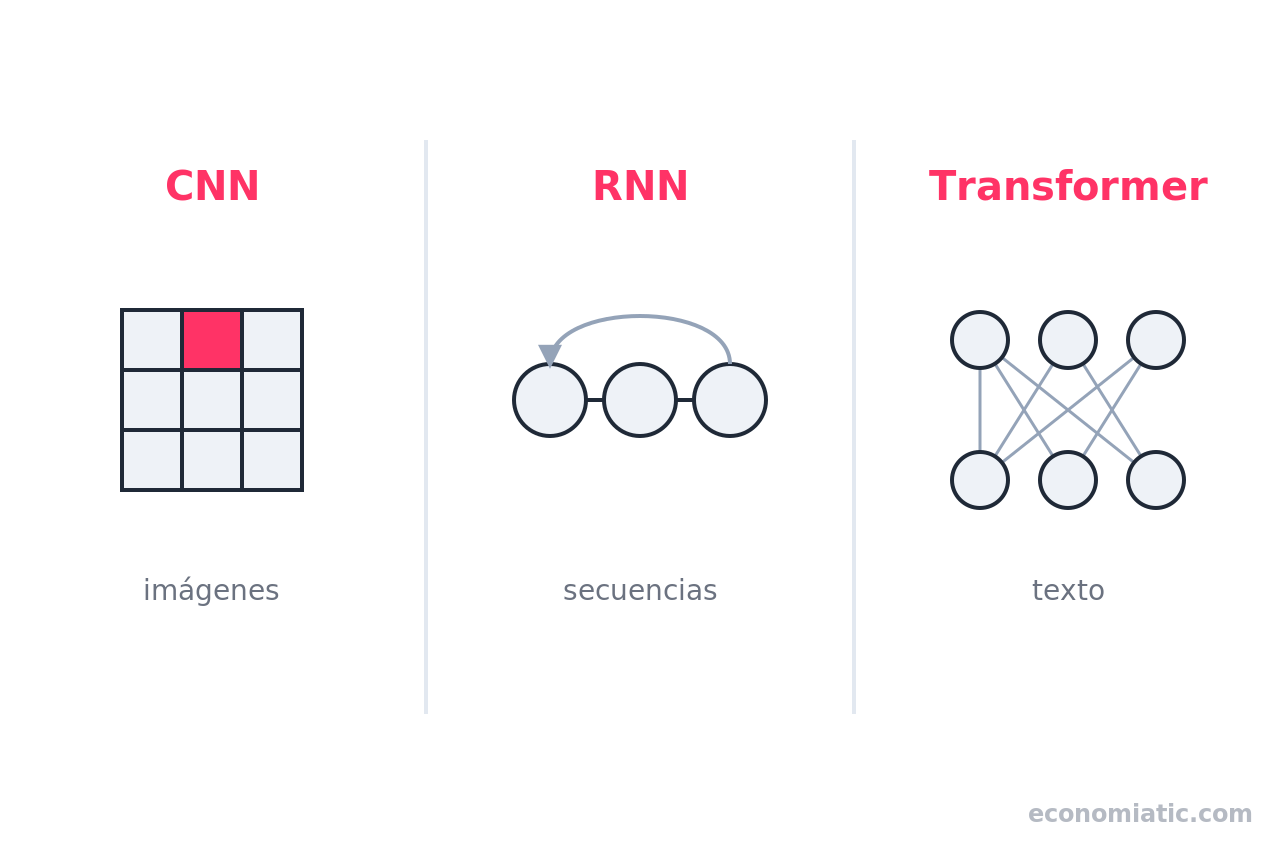
Las redes neuronales convolucionales (CNN, por Convolutional Neural Networks) están diseñadas para imágenes: en vez de mirar todos los píxeles a la vez, deslizan pequeños «filtros» por la imagen para detectar bordes, texturas y formas, capa a capa.
Es la arquitectura detrás del reconocimiento facial de tu móvil y de buena parte del diagnóstico médico por imagen.
Las redes neuronales recurrentes (RNN, por Recurrent Neural Networks) procesan datos en secuencia —texto, audio, series temporales— y tienen una forma de «memoria» que conecta cada paso con los anteriores.
Esa memoria les permite tener en cuenta el contexto: para entender la palabra «banco» hay que mirar las palabras de alrededor. Durante años fueron el estándar en traducción y reconocimiento de voz.
Los transformers son una arquitectura de red neuronal, presentada en 2017, que procesa secuencias enteras en paralelo mediante un mecanismo de «autoatención» (self-attention), en lugar de palabra por palabra como las RNN.
El artículo fundacional, Attention Is All You Need de Vaswani y sus colegas, eliminó la recurrencia y las convoluciones y dejó solo la atención4.
El resultado: modelos mucho más rápidos de entrenar y capaces de captar relaciones a larga distancia en un texto.
Es la base de prácticamente toda la IA generativa actual. Los LLM como ChatGPT, CLaude o Gemini son, en esencia, redes neuronales gigantes basadas en la arquitectura transformer.
Las redes neuronales sirven para encontrar patrones en grandes volúmenes de datos y tomar decisiones a partir de ellos: clasificar, predecir, reconocer y generar.
Hoy están integradas en servicios que usas a diario, casi siempre sin que se note que hay una red detrás.
A tener en cuenta: Entrenar los modelos punteros cuesta cantidades enormes de dinero y energía, y requiere volúmenes de datos al alcance de muy pocas organizaciones.
La mayoría de empresas no entrena redes desde cero; usa modelos ya entrenados a través de servicios en la nube. Saber qué hay debajo ayuda a usarlos con criterio.
Este es el triángulo de términos que más confusión genera, así que vamos a cerrarlo con claridad. No son sinónimos ni compiten entre sí: son círculos concéntricos, uno dentro de otro.
| Término | Qué es | Relación |
|---|---|---|
| Inteligencia artificial (IA) | El campo más amplio: máquinas que realizan tareas que asociamos a la inteligencia | El círculo grande que contiene todo lo demás |
| Machine learning | Una rama de la IA: sistemas que aprenden de los datos | Dentro de la IA |
| Redes neuronales | Una técnica dentro del machine learning, inspirada en el cerebro | Dentro del machine learning |
| Deep learning | Redes neuronales con muchas capas ocultas | Un subconjunto de las redes neuronales |
Dicho en una frase: las redes neuronales son una técnica dentro del machine learning, que a su vez es una rama de la inteligencia artificial; y cuando una red neuronal tiene muchas capas, lo que hacemos es deep learning.
No hay frontera mágica: la diferencia entre una red «normal» y una «profunda» es, simplemente, cuántas capas ocultas tiene.
Es un programa que aprende a reconocer patrones a base de ver ejemplos, en lugar de seguir reglas escritas a mano. Organiza pequeñas unidades de cálculo en capas y va ajustando las conexiones entre ellas hasta acertar. Si le enseñas miles de fotos de gatos, acaba reconociendo gatos sin que nadie le haya descrito qué es un gato.
No: se inspira en el cerebro, pero no lo replica. Una neurona artificial es una función matemática, no una célula viva. El cerebro tiene unos 86.000 millones de neuronas, consume poquísima energía y aprende de pocos ejemplos; una red neuronal necesita muchísimos datos y mucha potencia de cálculo.
No: la red neuronal es una técnica dentro de la inteligencia artificial, no la IA entera. La IA es el campo amplio; dentro está el machine learning; y dentro de él, las redes neuronales son una de las técnicas disponibles. Cuando esa red tiene muchas capas, hablamos de deep learning.
Solo calcula: ajusta números para minimizar el error, no comprende el significado. Cuando un modelo responde, está estimando qué salida es más probable según los patrones que aprendió, no razonando sobre el mundo. Por eso puede acertar con enorme precisión y, a la vez, equivocarse con total seguridad fuera de lo que vio al entrenar.
Porque Hopfield y Hinton sentaron, desde la física, las bases del aprendizaje automático con redes neuronales. Hopfield creó una memoria asociativa usando conceptos de física de materiales y Hinton desarrolló la máquina de Boltzmann con física estadística. Su trabajo de los años 80 hizo posible la revolución del deep learning posterior.
Una red neuronal no es un cerebro en una caja ni una máquina que piensa: es una estructura matemática que aprende a detectar patrones ajustando millones de números —los pesos— hasta minimizar sus errores.
Esa idea, nacida en 1943 y consagrada con un Nobel de Física en 2024, es hoy el motor de casi todo lo que llamamos inteligencia artificial, desde el filtro antifraude de tu banco hasta el chatbot que redacta correos.
Entender el mecanismo —entradas, pesos, capas, retropropagación— y, sobre todo, tener claro qué no hace una red neuronal es la mejor vacuna contra el ruido.
La próxima vez que leas que una IA «piensa como un humano», ya sabes qué responder: no piensa, calcula. Y eso, bien usado, ya es bastante.
