
En 2023, un abogado de Nueva York presentó ante un juez un escrito con seis sentencias que respaldaban su caso.
El problema: ninguna existía. ChatGPT se las había inventado, con nombres, números de expediente y citas de aspecto impecable.
El despacho acabó sancionado, y el caso —Mata contra Avianca— se convirtió en el ejemplo de manual de lo que son las alucinaciones de IA.1
No es una anécdota aislada. Es la consecuencia directa de cómo funcionan estas herramientas.
Entender qué son las alucinaciones de IA, por qué ocurren y cómo reducirlas no es un tecnicismo: es la diferencia entre usar la inteligencia artificial como un asistente competente o tropezar con un error que parece verdad.
Resumen
- Una alucinación de IA es una respuesta falsa o inventada que el modelo presenta con total seguridad, porque optimiza qué texto es plausible, no qué texto es verdadero.
- Tienen causas estructurales —predicción estadística, datos de entrenamiento limitados, el incentivo a adivinar— y no desaparecen con modelos mejores: los benchmarks aún muestran tasas superiores al 10 % en tareas largas.
- Se reducen anclando el modelo a fuentes fiables (RAG), aportando contexto, usando prompts que admitan la duda y verificando siempre los datos importantes.
En este artículo verás qué significa exactamente el término, las causas reales detrás de cada invento, los tipos que existen, ejemplos que han salido caros y un protocolo concreto para protegerte cuando trabajas con IA.
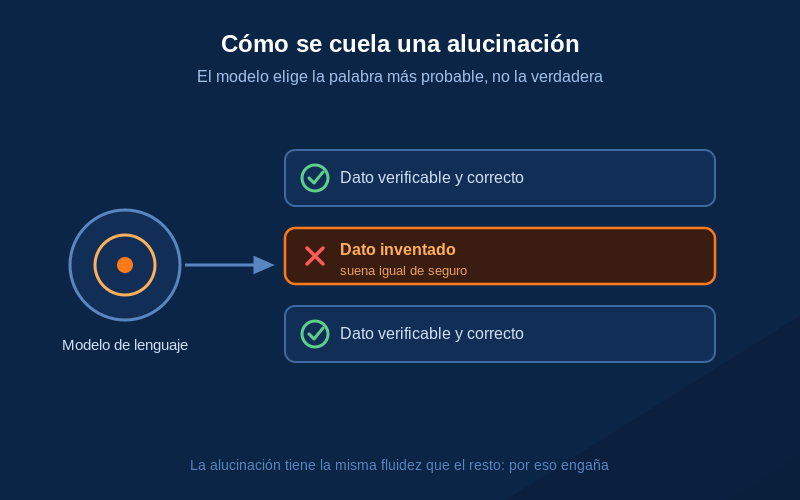
Una alucinación de IA es una respuesta generada por un modelo de inteligencia artificial —normalmente un modelo de lenguaje— que es factualmente incorrecta, carece de sentido o no está fundamentada en sus datos ni en la fuente proporcionada, pero se presenta con la misma fluidez y seguridad que una respuesta correcta.2 El término se aplica sobre todo a la IA generativa.
La clave está en esa última parte: la confianza. Un buscador que no encuentra algo devuelve "sin resultados". Un modelo de lenguaje, en cambio, casi nunca dice "no lo sé". Rellena el hueco con la continuación más verosímil, y lo hace con el mismo tono asertivo que usaría para un dato cierto.3
El nombre es una metáfora, y no del todo afortunada. La IA no "percibe" cosas que no existen como una persona con una alucinación; produce texto plausible sin anclaje en la realidad. Por eso algunos investigadores prefieren el término confabulación, más preciso para describir un sistema que inventa para mantener la coherencia del discurso.
Conviene situar el fenómeno. Las alucinaciones aparecen en cualquier IA generativa —texto, imágenes, código, audio—, pero son más visibles y más estudiadas en los modelos de lenguaje de gran tamaño (LLM) que hay detrás de ChatGPT, Claude o Gemini.
Son un límite estructural de la tecnología, no un fallo de una marca concreta.
Las alucinaciones no son un error aleatorio que se cuela de vez en cuando, sino un síntoma de cómo se construye y se entrena un modelo de lenguaje.4 Hay cuatro causas que conviene distinguir, porque cada una se mitiga de forma distinta.
Un modelo de lenguaje funciona prediciendo, palabra a palabra, la continuación más probable de un texto. Su objetivo técnico es la plausibilidad estadística, no la veracidad.
Cuando los patrones que aprendió apuntan a una respuesta que suena bien pero es falsa, el modelo la genera igual: no tiene un mecanismo interno que separe "lo que es verdad" de "lo que parece verdad".2
El conocimiento de un modelo está limitado por los datos de entrenamiento con los que se construyó.
Si un tema está mal representado, desactualizado o directamente ausente, el modelo no lo reconoce como un vacío: improvisa. A esto se suma la fecha de corte —el momento en que termina su entrenamiento—, que hace que invente sobre hechos posteriores salvo que se conecte a fuentes externas.
Y si esos datos están sesgados, el modelo no solo improvisa: hereda esos sesgos algorítmicos y los reproduce con la misma seguridad.
Una investigación de OpenAI de 2025 aporta el matiz más revelador: los modelos alucinan en parte porque el entrenamiento y la evaluación premian adivinar por encima de admitir incertidumbre.5
Como a los modelos se los puntúa por acertar, responder "no lo sé" penaliza la nota tanto como equivocarse, mientras que una respuesta inventada al menos puede acertar por azar.
El resultado es un sistema optimizado para parecer un buen examinando: arriesga siempre.
Por último, la propia configuración influye. El parámetro de "temperatura" controla cuánta variabilidad introduce el modelo al elegir cada palabra; valores altos favorecen respuestas más creativas, pero también más propensas a desviarse de los datos precisos. Más creatividad significa, casi siempre, más riesgo de invención.
No todas las alucinaciones son iguales, y distinguirlas ayuda a saber dónde vigilar. La división más útil separa las que contradicen el mundo de las que contradicen la fuente que se le ha dado al modelo.2
| Tipo | Qué significa | Ejemplo |
|---|---|---|
| Factual | La respuesta contradice hechos verificables del mundo real | Atribuir un libro a un autor que no lo escribió |
| De fidelidad (faithfulness) | La respuesta contradice o se desvía de la fuente o el contexto aportado | Resumir un documento añadiendo datos que no aparecen en él |
| Intrínseca | El contenido inventado contradice la propia entrada del usuario | Cambiar una cifra que el usuario acaba de proporcionar |
| Extrínseca | El contenido no es verificable contra ninguna fuente disponible | Citar un estudio que no existe |
La distinción importa en la práctica:
El terreno legal se ha convertido en el escaparate de las alucinaciones de IA, porque es donde una cita inventada tiene consecuencias inmediatas y documentadas.
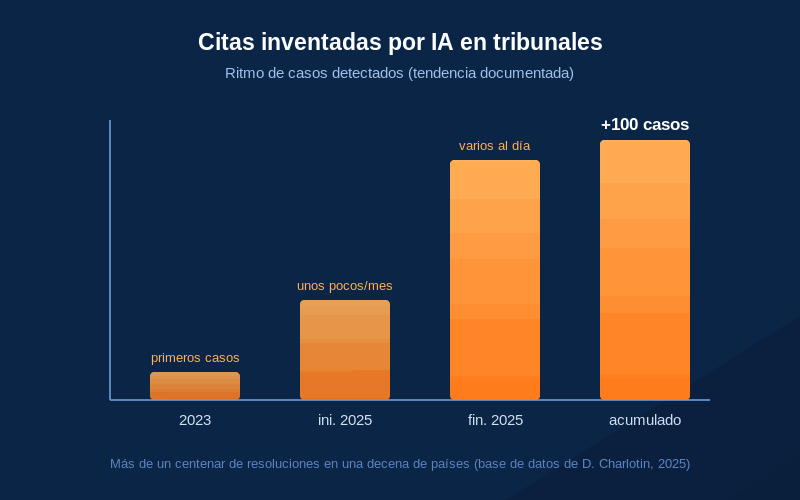
El investigador Damien Charlotin mantiene una base de datos de estos casos: para 2025 había recopilado más de un centenar de resoluciones judiciales, en una decena de países, en las que se detectaron citas fabricadas por IA, y el ritmo pasó de unos pocos al mes a varios al día.6
El caso fundacional sigue siendo Mata contra Avianca (2023): el abogado Steven Schwartz presentó un escrito con seis precedentes inexistentes generados por ChatGPT, y el tribunal sancionó al despacho con 5.000 dólares.1
En California, otro letrado incluyó 23 citas en una apelación, de las cuales 21 eran inventadas; la sanción ascendió a más de 31.000 dólares.6
En España el fenómeno también ha llegado a los tribunales.
En un caso, un abogado fundamentó un escrito citando artículos del Código Penal de Colombia en lugar del español —un calco de ChatGPT—; el Tribunal Superior de Justicia de Navarra optó por no sancionar, atendiendo a la relativa novedad de estas tecnologías.7 La clemencia, previsiblemente, durará poco.
Existe una creencia extendida que conviene desmontar: que las alucinaciones son una enfermedad infantil de la IA que desaparecerá con modelos más grandes y mejores. La evidencia apunta en otra dirección.
El trabajo de OpenAI sostiene que las alucinaciones son, en buena medida, un resultado estadístico inevitable del modo en que estos sistemas se entrenan y se evalúan, no un defecto puntual que se corrige con más datos.5
De hecho, los rankings independientes muestran que el problema no se ha resuelto: según el benchmark de Vectara, a fecha de 2026 los modelos punteros aún superan el 10 % de tasa de alucinación al resumir documentos largos, y algunos modelos de razonamiento —que deberían ser más fiables— alucinan más que sus versiones estándar.8
Esto no significa que no haya progreso. El mismo ranking sitúa a los mejores modelos por debajo del 1 % en tareas acotadas.8 Significa que la mitigación es una práctica continua, no un parche que llegará en la próxima versión. La responsabilidad de verificar sigue, hoy, del lado humano.
No se pueden eliminar del todo, pero sí reducirlas de forma notable con una combinación de técnica y criterio. Estas son las palancas más efectivas, de la más potente a la más cotidiana.
La técnica más eficaz se llama generación aumentada por recuperación, o RAG (retrieval-augmented generation): consiste en conectar el modelo a una base de datos o a documentos de confianza para que responda a partir de información real y verificable, en lugar de tirar solo de su memoria.3
Es el estándar de la industria para reducir alucinaciones, porque ataca la causa raíz: le da al modelo de dónde sacar la respuesta.
En la misma lógica de anclaje, cuanto mejor contexto le des al modelo, menos tiene que inventar. Pegar el documento de referencia en el prompt, especificar el marco y pedirle que se ciña a lo aportado reduce el margen de improvisación.
Aquí encaja también la memoria persistente para IA —la capacidad del sistema de retener datos tuyos o de tu proyecto entre sesiones—, pero con un matiz importante. Ayuda con un subtipo concreto de alucinación: la que surge cuando el modelo reinventa contexto porque no lo recuerda.
No resuelve las causas de fondo y tiene un riesgo propio: si la memoria almacena un dato erróneo, el modelo lo repetirá como verdad. Bien usada refuerza el anclaje; mal usada, fija el error.
Mucho se gana en la propia instrucción. Pedir explícitamente "responde solo si estás seguro y, si no lo sabes, dilo", exigir que cite las fuentes o pedirle que revise su propia respuesta reduce las invenciones, porque contrarresta el sesgo a adivinar.5
Para datos sensibles, bajar la temperatura del modelo también ayuda.
Ninguna técnica sustituye al último filtro: el humano. Trata toda cifra, cita, fecha o nombre propio que produzca una IA como un borrador pendiente de confirmar en la fuente original. La regla práctica es simple: si el dato importa, se comprueba.
Si eres profesional, autónomo o gestionas una pyme, las alucinaciones no son un debate teórico: son el motivo por el que no puedes delegar a ciegas. El asistente que redacta tu propuesta, resume una reunión o responde a un cliente puede colar un dato falso con una seguridad indistinguible de la de un dato cierto.
La implicación práctica es clara:
Cuanto mayor sea el coste de equivocarse, más estricto debe ser el control.
El valor, al final, no está en si la herramienta es infalible —no lo es—, sino en saber cuándo confiar y cuándo comprobar. Ese criterio es, hoy, la verdadera competencia profesional frente a la IA.
Es cuando una inteligencia artificial te da una respuesta falsa o inventada como si fuera cierta. No miente a propósito: genera el texto que estadísticamente parece más probable, aunque no se corresponda con la realidad. El problema es que lo hace con el mismo tono seguro que usaría para un dato correcto.
Porque optimiza qué texto es más probable, no qué texto es verdadero. Cuando no dispone de información fiable, rellena el hueco con la continuación más verosímil en lugar de admitir que no lo sabe. Además, la forma en que se entrena premia arriesgar una respuesta antes que reconocer incertidumbre.
No con la tecnología actual: son un límite estructural de los modelos de lenguaje. Se pueden reducir mucho con técnicas como RAG, buenos prompts y verificación, pero no eliminar del todo. Los rankings independientes muestran que incluso los mejores modelos siguen alucinando en cierto porcentaje de las respuestas.
Desconfía de cualquier dato concreto —cifras, citas, fechas, nombres o fuentes— y compruébalo en su origen. Las alucinaciones suelen aparecer en detalles verificables presentados con seguridad. Si pides a la IA que cite la fuente y esta no existe o no dice lo que afirma, estás ante una alucinación.
RAG (generación aumentada por recuperación) conecta el modelo a fuentes de información fiables para que responda a partir de datos reales. En lugar de generar la respuesta solo desde su memoria, el modelo recupera documentos verificables y se apoya en ellos. Es la técnica más eficaz para reducir invenciones y el estándar de la industria.
