
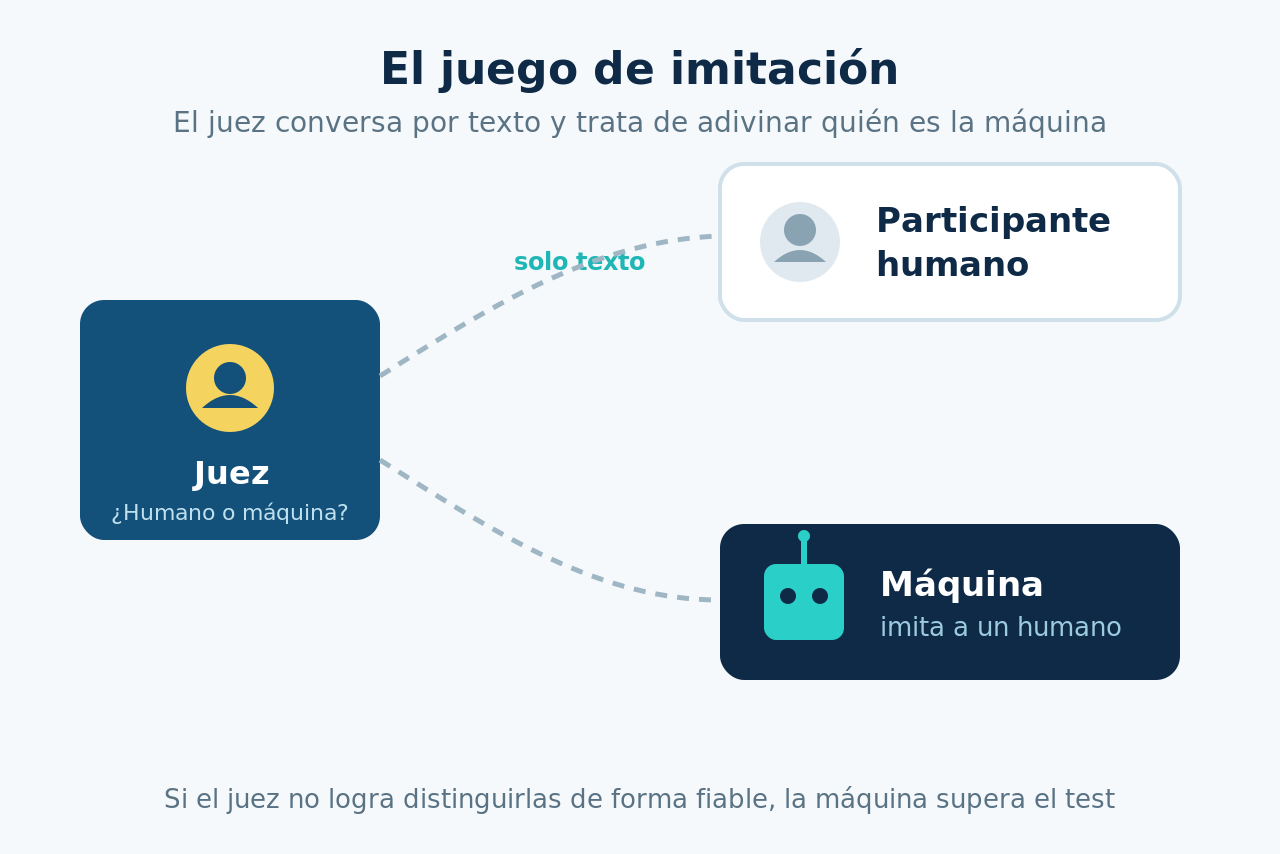
Definición rápida: el test de Turing es una prueba propuesta por Alan Turing en 1950 para decidir si una máquina exhibe un comportamiento inteligente indistinguible del humano.
Un juez conversa por escrito con una persona y con una máquina; si no logra distinguir cuál es cuál, la máquina supera la prueba.
Durante setenta años fue un experimento mental fascinante pero remoto: ninguna máquina se acercaba a engañar a un juez atento.
En 2025 eso cambió. Un estudio de la Universidad de California en San Diego concluyó que GPT-4.5 era tomado por humano el 73% de las veces, más a menudo incluso que las personas reales con las que competía1.
Conviene entender qué mide realmente esta prueba antes de celebrar (o temer) el titular.
No comprueba si una máquina piensa, sino si puede parecer que lo hace. Esa distinción —entre imitar y entender— es justo lo que lo ha convertido en el experimento más citado y más malinterpretado de la historia de la inteligencia artificial.
En este artículo verás de dónde viene, cómo funciona, qué críticas ha recibido y qué significa que un modelo de lenguaje lo supere en 2026.
El test de Turing es un método para evaluar la inteligencia de una máquina basándose en su capacidad de mantener una conversación indistinguible de la de un ser humano. Si un juez que interactúa solo mediante texto no puede determinar con fiabilidad si habla con una persona o con una máquina, se considera que la máquina ha pasado la prueba2.
Lo propuso el matemático británico Alan Turing en 1950, en un artículo titulado Computing Machinery and Intelligence, publicado en la revista Mind2.
Turing quería responder a una pregunta espinosa —«¿pueden pensar las máquinas?»— pero la consideró demasiado ambigua para abordarla de frente. Términos como «pensar» o «máquina» se prestan a discusiones interminables.
Su solución fue elegante: sustituir esa pregunta filosófica por una prueba práctica y observable.
En lugar de definir qué es pensar, propuso medir si una máquina puede comportarse de forma indistinguible de alguien que piensa. Desplazó el debate del terreno de la metafísica al de la conducta.
Por eso la prueba es, en el fondo, un ejercicio de imitación, no de conciencia. No pregunta qué ocurre dentro de la máquina, sino qué efecto produce fuera.
Esta es la idea que conviene retener para entender todo lo demás.
El test de Turing funciona como un juego de imitación a tres bandas:
El juez conversa por escrito con ambos sin verlos y debe adivinar cuál es la persona. Si la máquina logra que el juez la confunda con el humano con suficiente frecuencia, supera la prueba2.
Turing lo bautizó como the imitation game, y su diseño tiene matices que suelen perderse en las versiones populares. La interacción es siempre textual —Turing imaginó algo parecido a un teletipo— precisamente para que la voz o el aspecto no contaminen el juicio.
Lo único que se evalúa es la capacidad lingüística y conversacional.
¿Cuándo se considera superada? Turing no fijó una nota de corte rígida, pero sí hizo una predicción concreta: aventuró que hacia el año 2000 las máquinas serían capaces de engañar a un juez medio durante cinco minutos en torno al 30% de las veces2.
Ese umbral del 30% se ha convertido en la vara de medir convencional, aunque conviene recordar que era una estimación, no una definición formal de la prueba.
La historia de esta prueba es la de máquinas que se acercaron al engaño por caminos muy distintos: unas explotando trucos psicológicos, otras mediante una potencia estadística sin precedentes.
Repasar sus hitos ayuda a entender por qué el resultado de 2025 es a la vez esperado y sorprendente.
El primer hito llegó en 1966 con ELIZA, un programa creado por Joseph Weizenbaum en el MIT que imitaba a un psicoterapeuta reformulando las frases del usuario como preguntas3.
ELIZA no entendía nada, pero muchos usuarios le atribuyeron comprensión y hasta empatía. Ese fenómeno —proyectar inteligencia sobre un sistema simple— se conoce desde entonces como «efecto ELIZA».
El caso más mediático llegó en 2014, cuando un chatbot llamado Eugene Goostman fue presentado como el primero en pasar el test en un certamen de la Royal Society de Londres, al convencer al 33% de los jueces4.
La hazaña fue muy discutida: el programa adoptaba la personalidad de un niño ucraniano de 13 años, lo que justificaba sus errores de gramática y sus lagunas de conocimiento como propios de un adolescente que no hablaba inglés nativo.
El salto definitivo lo dieron los grandes modelos de lenguaje.
En 2025, los investigadores Cameron Jones y Benjamin Bergen, de la Universidad de California en San Diego, sometieron a cuatro sistemas a una prueba controlada de tres participantes con conversaciones de cinco minutos1.
Cuando se le indicó que adoptara una personalidad humana, GPT-4.5 fue identificado como el humano el 73% de las veces.
Es la primera evidencia experimental sólida de que un sistema supera la prueba en su formato clásico.
| Hito | Año | Resultado | Por qué importa |
|---|---|---|---|
| ELIZA | 1966 | Engañó a usuarios sin proponérselo | Reveló el «efecto ELIZA»: proyectamos comprensión sobre máquinas simples |
| Eugene Goostman | 2014 | 33% de los jueces engañados | Primer «aprobado» reclamado, pero con truco de persona y muy cuestionado |
| GPT-4o | 2025 | 21% (sin instrucción de persona) | Sin un rol asignado, los modelos rinden mucho peor |
| GPT-4.5 | 2025 | 73% (con instrucción de persona) | Primera superación robusta del test clásico de tres bandas |
Un detalle del estudio de 2025 es revelador: sin la instrucción de fingir una personalidad, la tasa de GPT-4.5 caía al 36% y la de GPT-4o se quedaba en el 21%, por debajo incluso de algunas estimaciones para humanos1.
El «aprobado» no depende solo de la potencia del modelo, sino de cómo se le pide que actúe.
No toda la familia del test de Turing sirve para evaluar máquinas: algunas variantes invierten los papeles y ponen a la máquina a juzgar al humano.
El ejemplo más cotidiano es el CAPTCHA, esa casilla de «no soy un robot» que rellenas a diario.
Un test de Turing inverso es aquel en el que una máquina, en lugar de un humano, actúa como juez para determinar si su interlocutor es una persona o un programa.
CAPTCHA es precisamente eso: sus siglas en inglés significan «prueba de Turing pública y completamente automatizada para distinguir ordenadores de humanos».
La paradoja es que estas pruebas se vuelven cada vez más difíciles a medida que la IA mejora. Cuando una máquina puede leer texto distorsionado o reconocer imágenes mejor que tú, el CAPTCHA tradicional deja de funcionar, y por eso han evolucionado hacia el análisis de tu comportamiento —cómo mueves el ratón, cómo escribes— en vez de plantear acertijos visuales.
Existe una conclusión muy extendida que conviene desmontar: que si una IA pasa el test de Turing, entonces «es inteligente» o «piensa como un humano».
La prueba no demuestra eso. Mide indistinguibilidad conversacional, no comprensión ni conciencia.
La objeción más célebre la formuló el filósofo John Searle en 1980 con el experimento mental de la habitación china5.
Imagina a una persona que no sabe chino encerrada en una habitación con un manual de reglas para responder a mensajes en chino manipulando símbolos.
Desde fuera, sus respuestas parecen las de alguien que domina el idioma; por dentro, no entiende ni una palabra.
Searle sostiene que un ordenador hace exactamente eso: manipula símbolos según reglas sin comprender su significado.
Aplicado a los modelos actuales, el argumento sigue vigente. Un LLM genera respuestas convincentes prediciendo, palabra a palabra, qué continuación es más probable, pero no tiene un modelo del mundo ni intención.
Pasar el test demuestra que imita el lenguaje humano con maestría, no que haya pensamiento detrás.
Por eso muchos investigadores lo consideran hoy más un hito cultural que una medida científica útil de la inteligencia.
Evalúa la capacidad de engañar, que no es lo mismo que la capacidad de razonar. Una máquina puede sonar humana y carecer por completo de entendimiento, igual que puede razonar bien sobre un problema y delatarse al instante como máquina.
Aunque haya quedado superado como criterio de inteligencia, la prueba conserva un valor que pocas tienen: nos obliga a preguntarnos qué esperamos exactamente de una máquina y qué consecuencias tiene que ya no podamos distinguirla de nosotros al otro lado de una pantalla.
La implicación práctica es inmediata. Si un sistema puede hacerse pasar por humano de forma fiable, la frontera entre interlocutor real y artificial se difumina en la atención al cliente, en las redes sociales y en el fraude.
Saber que esto ya es técnicamente posible cambia cómo deberíamos diseñar y regular estos sistemas.
El propio estudio de 2025 lo apunta: el riesgo no es que las máquinas «piensen», sino que sean lo bastante persuasivas como para sustituir a personas sin que nadie lo note1.
El debate se desplaza así de la filosofía —¿puede pensar una máquina?— a la ética y el diseño: ¿debe una máquina ocultar que lo es?
Esa, y no la pregunta original de Turing, es probablemente la cuestión que más nos ocupará en los próximos años.
Lo propuso el matemático británico Alan Turing en 1950. Lo presentó en su artículo Computing Machinery and Intelligence, publicado en la revista Mind. Turing, considerado uno de los padres de la informática, buscaba una forma práctica de abordar la pregunta de si las máquinas pueden pensar.
Sirve para evaluar si una máquina puede exhibir un comportamiento conversacional indistinguible del de un humano. Más que una herramienta técnica precisa, hoy funciona como referencia conceptual e histórica para discutir qué entendemos por inteligencia artificial. Su utilidad real es provocar el debate sobre los límites entre imitar y comprender.
Sí: en 2025, un estudio de UC San Diego concluyó que GPT-4.5 superó el test clásico al ser tomado por humano el 73% de las veces. Antes, en 2014, el chatbot Eugene Goostman fue presentado como el primero en pasarlo al engañar al 33% de los jueces, aunque ese resultado fue muy cuestionado por basarse en una personalidad que justificaba sus errores.
Depende del modelo y de cómo se le indique actuar. En el estudio de 2025, GPT-4.5 alcanzó un 73% cuando se le pidió adoptar una personalidad humana, pero solo un 36% sin esa instrucción; GPT-4o se quedó en el 21%. Pasar la prueba no garantiza comprensión: el modelo imita el lenguaje, no razona como una persona.
Es un experimento mental de John Searle (1980) que cuestiona el test de Turing. Plantea que una máquina puede manipular símbolos y producir respuestas correctas sin entender su significado, igual que alguien que sigue un manual para responder en chino sin saber el idioma. Demuestra que parecer inteligente no implica comprender.
Es una variante en la que la máquina, no el humano, actúa como juez para distinguir si su interlocutor es una persona o un programa. El ejemplo más común es el CAPTCHA, que verifica que quien navega es humano. Su nombre completo en inglés significa, de hecho, «prueba de Turing pública y completamente automatizada».
