
Durante un par de años, la habilidad estrella para sacar partido a la inteligencia artificial fue encontrar la frase exacta: el prompt perfecto.
Desde 2025 el foco se ha desplazado a algo más amplio. Ya no se trata solo de qué le pides al modelo, sino de todo lo que el modelo tiene delante cuando responde: las instrucciones de fondo, lo que recuerda de la conversación, los datos que ha consultado, las herramientas que puede usar.
Esa disciplina —diseñar y gestionar ese conjunto completo de información— es el context engineering, y se ha convertido en la habilidad central para construir sistemas de IA que funcionen de verdad, sobre todo agentes.
Lo importante
- El context engineering (o ingeniería de contexto) es la disciplina de diseñar y gestionar todo el conjunto de información que un modelo de lenguaje ve en cada paso: instrucciones de sistema, historial, memoria, datos recuperados (RAG) y herramientas, no solo el prompt aislado.
- Anthropic lo describe como "la progresión natural del prompt engineering": el foco pasa de escribir la frase perfecta a decidir qué configuración de contexto produce el comportamiento deseado.
- Importa sobre todo en los agentes de IA, que operan en bucle durante muchos pasos; y choca con un límite real, el context rot: añadir más contexto no garantiza mejores respuestas.
Andrej Karpathy lo resumió en junio de 2025 con una imagen útil:
Si el prompt engineering era dar con una frase corta, el context engineering es «el delicado arte y ciencia de llenar la ventana de contexto con la información justa para el siguiente paso»1.
No es un cambio de moda terminológica gratuito. Es un cambio de problema.
El context engineering, o ingeniería de contexto, es la disciplina de diseñar, seleccionar y mantener el conjunto de información (el «contexto») que recibe un modelo de lenguaje durante la inferencia para que produzca el comportamiento deseado.
Abarca las instrucciones de sistema, el historial, la memoria, los datos recuperados y las herramientas, no solo el prompt23.
Anthropic, que formalizó el término en septiembre de 2025, lo define como «el conjunto de estrategias para curar y mantener el conjunto óptimo de tokens (información) durante la inferencia de un LLM, incluida toda la demás información que pueda acabar ahí además de los prompts».
El «engineering» del nombre es literal: el problema es optimizar la utilidad de esos tokens frente a las limitaciones del modelo.
El contexto es todo lo que entra en la ventana de contexto del modelo en un momento dado: el espacio finito —medido en tokens— donde caben las instrucciones, la conversación y los datos sobre los que el modelo razona.
La ventana es como el escritorio de trabajo de la IA: lo que está encima se usa para responder; lo que no cabe, no existe para el modelo en ese instante.
A diferencia de un prompt, que es un objeto concreto y puntual, el contexto es un estado que evoluciona.

En una conversación o en un agente que da muchos pasos, esa información cambia en cada turno, y alguien (o algún sistema) tiene que decidir qué se queda y qué se descarta.
El contexto no es un bloque único, sino un ensamblaje de piezas que el context engineering coordina.
Anthropic enumera el estado completo como instrucciones de sistema, herramientas, datos externos e historial de mensajes; en la práctica conviene distinguir cinco componentes.
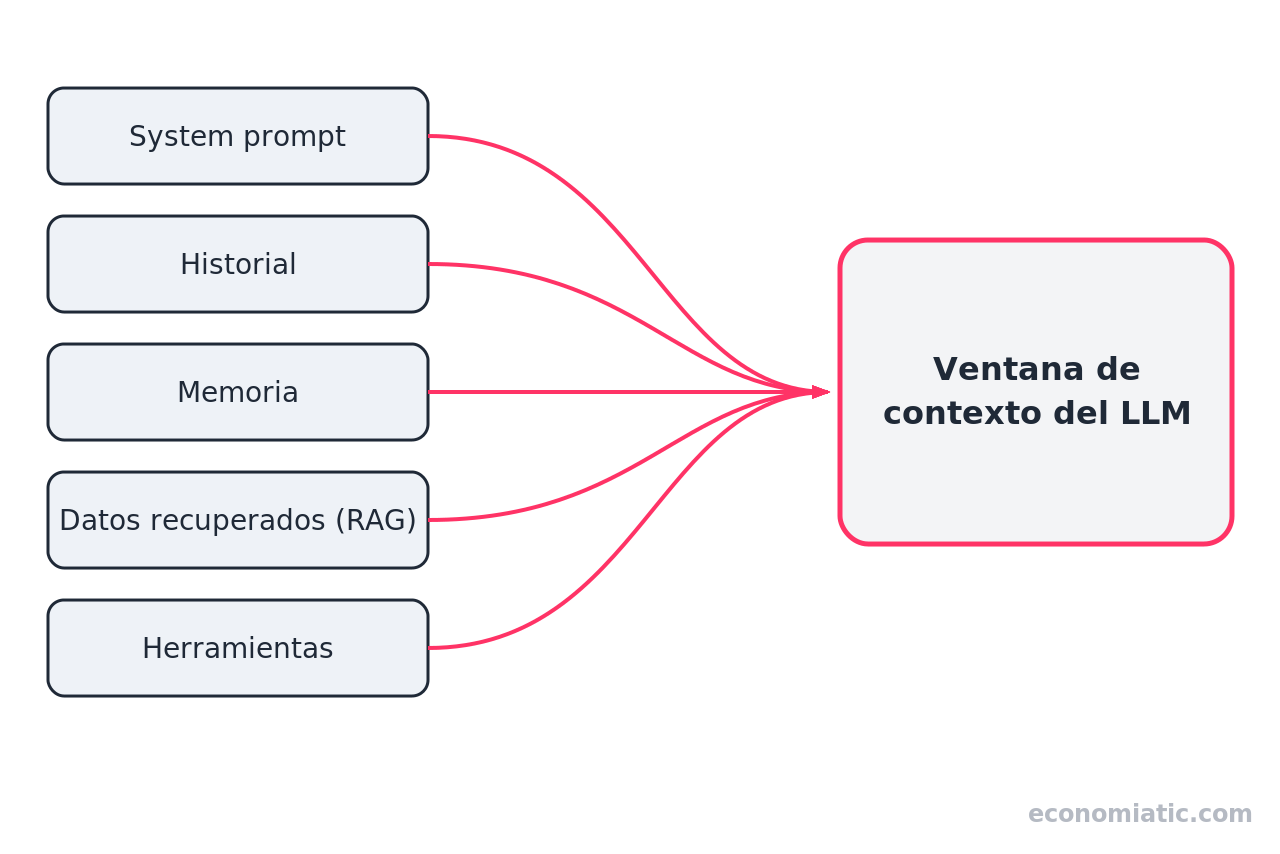
El system prompt sigue siendo importante —Anthropic recomienda escribirlo a la «altitud» justa: ni una lógica rígida llena de condicionales frágiles, ni una vaguedad que no oriente nada—. Pero ahora es una pieza más de un conjunto mayor.
El RAG, que recupera fragmentos relevantes de una base de conocimiento, y la memoria persistente, que conserva información entre sesiones, son las dos piezas que más han hecho crecer la complejidad del contexto.
La diferencia, en una frase:
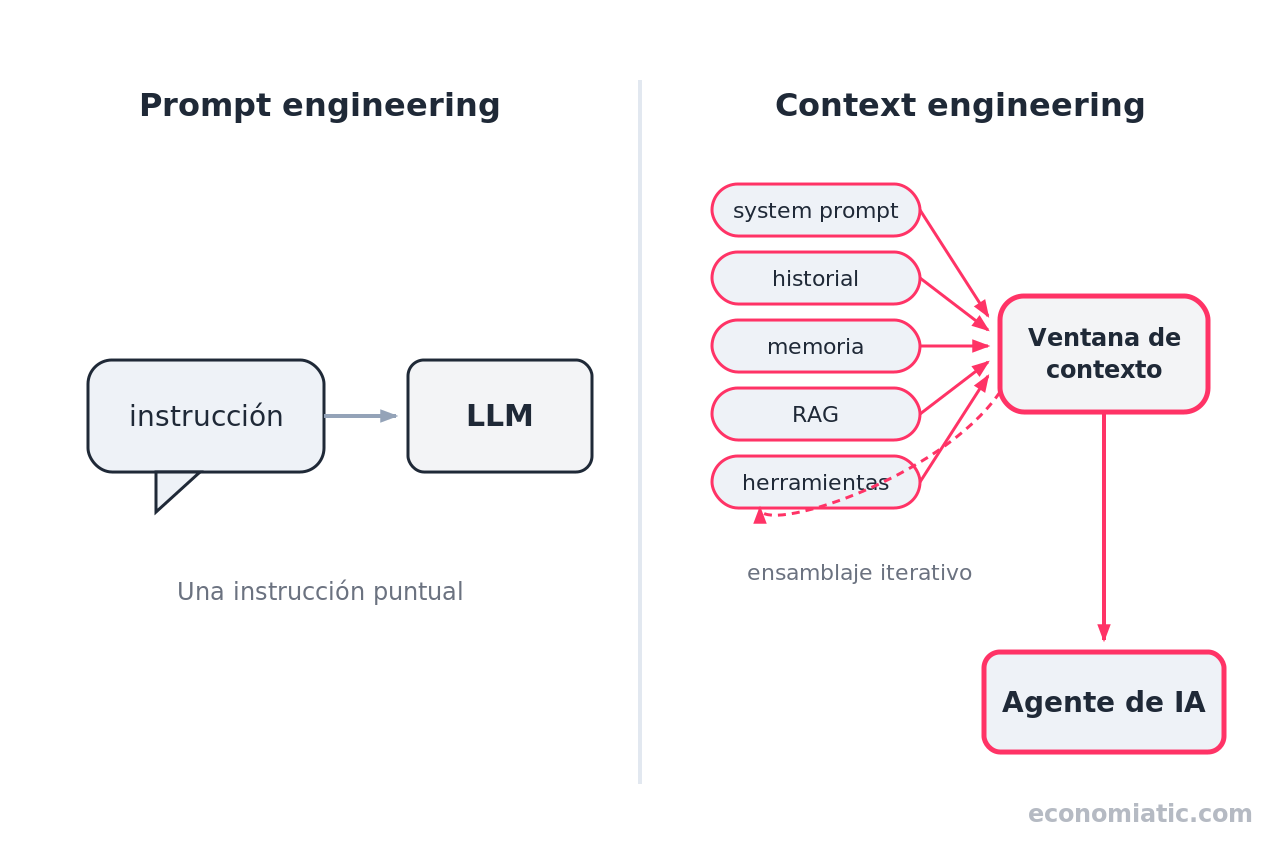
el prompt engineering optimiza qué le pides al modelo en una instrucción; el context engineering diseña todo lo que el modelo ve cuando responde.
Anthropic enmarca el segundo como «la progresión natural» del primero, no como su sustituto.
El prompt engineering es una tarea discreta —escribir un mensaje—; el context engineering es iterativo: la decisión de qué pasar al modelo se repite en cada paso.
Conviene no caer en el titular fácil de que «el prompt engineering ha muerto», que circula por foros y artículos divulgativos.
La realidad es más matizada:
Saber articular con claridad qué quieres de una IA sigue siendo una habilidad transferible y necesaria.4 Lo que ha cambiado es que, en sistemas complejos, esa instrucción es solo una parte del problema.
El prompt engineering no desaparece; se convierte en un componente del context engineering.
LangChain, una de las plataformas de referencia para construir aplicaciones con LLM, lo desglosa en cuatro operaciones que ayudan a entender el trabajo concreto:
El context engineering nace, sobre todo, de los agentes de IA: sistemas que usan un modelo de lenguaje para encadenar varios pasos de forma autónoma, llamando a herramientas en bucle.
Un chat de una sola pregunta apenas necesita gestión de contexto. Un agente que trabaja durante minutos u horas —migrando código, investigando un tema, analizando documentos— genera en cada paso nueva información que podría ser relevante para el siguiente, y hay que refinarla de forma continua.
Ahí es donde escribir el prompt perfecto deja de bastar. El reto pasa a ser arquitectónico:
Como recuerda Anthropic, si un ingeniero humano no sabría con certeza qué herramienta usar en una situación dada, no se puede esperar que el agente lo haga mejor.
Aquí conviene desmontar una intuición extendida: la idea de que cuanto más contexto le des al modelo, mejor responderá. Es falsa.
La investigación sobre el llamado context rot —la degradación del contexto— muestra que, a medida que aumenta el número de tokens de entrada, la capacidad del modelo para recuperar información con precisión disminuye, incluso cuando la ventana está lejos de llenarse.
El informe técnico de Chroma (julio de 2025) probó 18 modelos frontera —entre ellos GPT-4.1, Claude Opus 4 y Gemini 2.5— y halló que todos exhiben esa degradación en cada incremento de longitud analizado6.
No es un fallo puntual de un modelo concreto, sino una característica general.
La razón es arquitectónica: los modelos se basan en el transformer, donde cada token debe «atender» a todos los demás, lo que produce relaciones por pares que crecen con el cuadrado del número de tokens (n²)7. La atención del modelo es, en palabras de Anthropic, un «presupuesto» finito: cada token nuevo lo consume un poco.
La consecuencia práctica es clara y contraintuitiva:
Un buen context engineering no busca meter toda la información posible, sino el conjunto más pequeño de tokens de alta señal que maximice la probabilidad de la respuesta deseada. Menos, pero mejor elegido.
Para tareas que exceden la ventana de contexto, Anthropic describe tres técnicas que ya se usan en producción:
El RAG (generación aumentada por recuperación) es una técnica dentro del context engineering, no un sinónimo.
El RAG se encarga de traer fragmentos relevantes de una fuente externa a la ventana de contexto; el context engineering es la disciplina más amplia que decide qué se recupera, cuándo, junto a qué otras piezas (memoria, herramientas, instrucciones) y cómo se gestiona todo ese conjunto a lo largo del tiempo.
De hecho, la tendencia que describe Anthropic es a complementar el RAG clásico —que precarga datos antes de responder— con estrategias «just in time»: el agente mantiene referencias ligeras (rutas de ficheros, enlaces, consultas guardadas) y carga los datos dinámicamente durante la ejecución, igual que un humano no memoriza un archivo entero sino que lo consulta cuando lo necesita.
El survey académico más amplio sobre el tema, que analiza más de 1.400 artículos, sitúa precisamente el RAG, los sistemas de memoria y los sistemas multiagente como implementaciones que integran los componentes del context engineering.
Para una organización, el context engineering deja de ser teoría en cuanto se intenta poner la IA a trabajar en procesos reales.
Decidir qué información ve el modelo —y cuál se descarta— es lo que separa un piloto vistoso de un sistema fiable, y es la base de cualquier estrategia seria de IA para empresas.
El principio de «menos contexto, pero mejor elegido» tiene además una lectura económica directa: cada token cuesta.
Gestionar bien la memoria y el contexto repetido es la palanca principal para ahorrar tokens y optimizar el trabajo diario con asistentes como Claude sin perder calidad.
RECOMENDADO
Llevado a un flujo concreto, pongo el pipeline editorial de Economía TIC como ejemplo: Nuestra ingeniería de contexto nos permite crear contenido con IA (aunque siempre revisado por un humano) como el que estás leyendo de forma consistente en lugar de empezar de cero en cada sesión.
El context engineering no sustituye al prompt engineering: amplía el foco desde la frase perfecta hasta todo el entorno de información que rodea a una IA cuando decide qué responder.
Es la disciplina que ha hecho viables los agentes, y su principio rector es contraintuitivo —no se trata de dar más contexto, sino el más relevante—.
Si quieres entender qué hay debajo de todo esto, el siguiente paso natural es saber cómo funciona el modelo de lenguaje que procesa ese contexto y, antes incluso, qué es la inteligencia artificial que lo hace posible.
El context engineering es el trabajo de decidir toda la información que una IA tiene delante cuando responde, no solo la pregunta que le haces. Incluye las instrucciones de fondo, lo que recuerda de la conversación, los datos que consulta y las herramientas que puede usar. El objetivo es darle lo justo y relevante para que acierte.
El prompt engineering optimiza la instrucción concreta que escribes; el context engineering diseña todo el contexto que ve el modelo, del que el prompt es solo una parte. Anthropic describe el segundo como la evolución natural del primero. El prompt engineering sigue siendo útil, pero en sistemas complejos es un componente de un problema mayor.
Es la disciplina central para construir agentes, porque operan en bucle durante muchos pasos y generan información nueva que hay que gestionar continuamente. En un chat de una pregunta apenas importa; en un agente que trabaja durante horas, decidir qué contexto entra en cada paso determina si la tarea sale bien.
No: añadir más contexto puede empeorar el rendimiento, un fenómeno conocido como context rot. La investigación de Chroma demostró que los modelos pierden precisión al recuperar información a medida que crece el número de tokens, incluso sin llenar la ventana. La clave es la calidad y la relevancia del contexto, no la cantidad.
Para diseñar agentes y aplicaciones de IA, sí suele hacer falta perfil técnico; para entender y aplicar el concepto en el uso diario, no. Cualquiera puede mejorar sus resultados aportando contexto relevante y eliminando ruido. El context engineering avanzado —memoria, RAG, herramientas, compactación— pertenece al terreno de quien construye sistemas.
