
Definición rápida: un LLM (large language model o modelo de lenguaje de gran tamaño) es un tipo de inteligencia artificial entrenada con enormes cantidades de texto para entender y generar lenguaje humano. Son, de hecho, el motor que hace posible la IA generativa.
Funciona prediciendo, palabra a palabra, la continuación más probable de un texto.
Cada vez que escribes en ChatGPT, Claude o Gemini estás hablando con un LLM, aunque seguramente nunca te hayas parado a pensar qué hay detrás de esas tres letras.
La pregunta importa más de lo que parece: entender qué es un LLM es entender por qué estas herramientas resultan tan útiles para redactar un email y, a la vez, por qué se inventan datos con total seguridad.
No hace falta ser ingeniero para comprenderlo. Basta con seguir una idea sencilla: un LLM no busca la verdad, busca la palabra que probablemente viene después.
En este artículo verás qué significa exactamente el término, cómo funciona por dentro, para qué sirve, cuáles son los modelos más usados en 2026 y qué implica todo esto para tu trabajo.
Un LLM es un modelo de inteligencia artificial entrenado sobre cantidades masivas de texto —libros, artículos, código, conversaciones— para reconocer los patrones del lenguaje y generar respuestas coherentes. Su tarea técnica es una sola: dado un fragmento de texto, predecir cuál es el siguiente fragmento más probable1.
Las siglas vienen del inglés large language model. En español se traduce como modelo de lenguaje de gran tamaño, y ese "gran tamaño" no es decorativo. Define la categoría: hablamos de modelos con miles de millones de parámetros, entrenados con volúmenes de texto que ninguna persona podría leer en mil vidas.
La diferencia con un modelo de lenguaje tradicional está justamente ahí, en la escala. Los modelos pequeños predecían la siguiente palabra con un horizonte muy corto. Un LLM mantiene el hilo de un documento entero, capta matices de estilo y responde sobre temas que no estaban planteados de forma explícita en su entrenamiento2.
Conviene situar el término dentro de su familia. La inteligencia artificial (IA) es el campo general; el machine learning (aprendizaje automático) es la rama que aprende de datos; y un LLM es un tipo concreto de modelo de machine learning especializado en lenguaje. Cuando alguien dice "la IA me ha escrito esto", casi siempre se refiere a un LLM.
Un LLM funciona descomponiendo el texto en unidades llamadas tokens, convirtiéndolas en números y prediciendo, una y otra vez, qué token tiene más probabilidad de aparecer a continuación3. La analogía más fiel es el autocompletado del móvil llevado al extremo: el mismo principio, pero con miles de millones de parámetros y el contexto entero de la conversación.
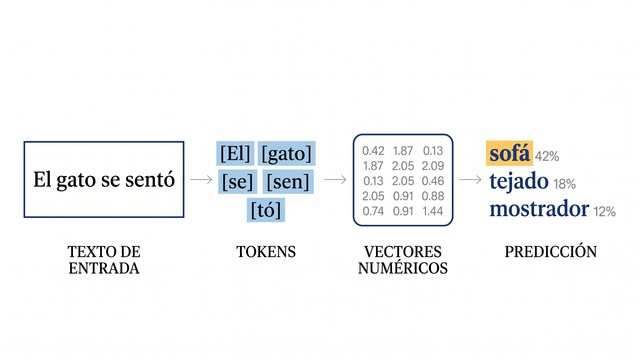
Vamos por partes, porque cada pieza tiene nombre propio.
Un token es la unidad mínima de texto que procesa el modelo: puede ser una palabra completa o un fragmento de palabra. Como regla aproximada, un token equivale a unas tres cuartas partes de una palabra en inglés3. El modelo nunca ve letras ni palabras tal como las vemos nosotros; ve secuencias de tokens convertidos en números.
Los parámetros son los valores numéricos que el modelo ajusta durante el entrenamiento y que codifican lo que ha aprendido. Un LLM tiene desde mil millones hasta cientos de miles de millones de parámetros5. Cuantos más parámetros bien entrenados, mayor capacidad de captar relaciones sutiles del lenguaje, aunque el tamaño por sí solo no garantiza calidad.
Casi todos los LLM actuales se apoyan en una red neuronal con una arquitectura llamada Transformer, presentada en 2017 por investigadores de Google en el artículo Attention Is All You Need6. Su mecanismo clave, la atención (self-attention), permite al modelo pesar qué palabras de un texto son relevantes entre sí, aunque estén lejos en la frase5.
Con ese mecanismo, el modelo calcula para cada posición una distribución de probabilidad sobre todos los tokens posibles y elige el más probable. Después lo añade al texto y repite el proceso3. Así, token a token, construye la respuesta que lees. Es el núcleo del procesamiento del lenguaje natural (NLP) moderno.
Conviene separar dos fases. El entrenamiento es el proceso, lento y costoso, en el que el modelo ajusta sus parámetros leyendo billones de tokens. La inferencia es lo que ocurre cuando tú lo usas: el modelo ya no aprende, solo aplica lo aprendido para generar la respuesta3. Por eso un LLM no "recuerda" tus conversaciones anteriores salvo que el sistema se las vuelva a pasar como contexto, el reto que aborda la memoria persistente para IA.
Un LLM sirve para cualquier tarea que se pueda expresar como texto de entrada y texto de salida, que son muchas más de las que parece. Su versatilidad es precisamente lo que lo ha convertido en una tecnología transversal y no en una herramienta de nicho5.
Entre los usos más extendidos están: redactar y resumir documentos, traducir entre idiomas, responder preguntas, generar y revisar código de programación, alimentar asistentes y chatbots de atención al cliente, y extraer información de grandes volúmenes de texto1.
Lo relevante para un profesional no es la lista, sino el patrón. Si una tarea consiste en transformar texto en otro texto —y buena parte del trabajo de oficina lo es—, un LLM probablemente puede asistirla. Ahí está su valor real, y también el origen de la tentación de delegarle más de la cuenta.
En 2026 conviven dos grandes familias: los modelos propietarios, accesibles a través del servicio de una empresa, y los modelos de código abierto, que cualquiera puede descargar y ejecutar. La elección entre uno y otro depende del control, el coste y la privacidad que necesites.
Estos son algunos de los grandes modelos de lenguaje más utilizados y la empresa que los desarrolla:
| Modelo (familia) | Empresa | Tipo | Rasgo distintivo |
|---|---|---|---|
| GPT-5 | OpenAI | Propietario | Modos de razonamiento ("thinking") para tareas complejas |
| Claude (Opus, Sonnet, Haiku) | Anthropic | Propietario | Foco en seguridad y contextos largos |
| Gemini 2.5 | Propietario | Ventana de contexto muy amplia | |
| Llama 4 | Meta | Abierto | Descargable y autoalojable, arquitectura eficiente |
| DeepSeek | DeepSeek | Abierto | Alto rendimiento en razonamiento a bajo coste |
| Mistral | Mistral AI | Abierto | Modelos europeos, multilingües y ligeros |
Dos conceptos aparecen al comparar modelos. El primero es la ventana de contexto: la cantidad de tokens que el modelo puede tener "en mente" a la vez; cuanto mayor, más texto puede analizar de una sola vez. Los modelos modernos ofrecen ventanas que van desde unos pocos miles hasta más de un millón de tokens3. El segundo es la multimodalidad: la capacidad de procesar no solo texto, sino también imágenes, audio o vídeo3. Ambos se han vuelto la norma, no la excepción.
Existe una idea muy extendida que conviene desmontar: que un LLM "entiende" lo que dice. No lo hace: imitar el lenguaje no es comprenderlo, la misma distinción que plantea el test de Turing. Un LLM no comprende el significado como una persona; calcula qué secuencia de tokens es más probable según los patrones que aprendió. Funciona asombrosamente bien, pero el mecanismo es estadístico, no consciente1.
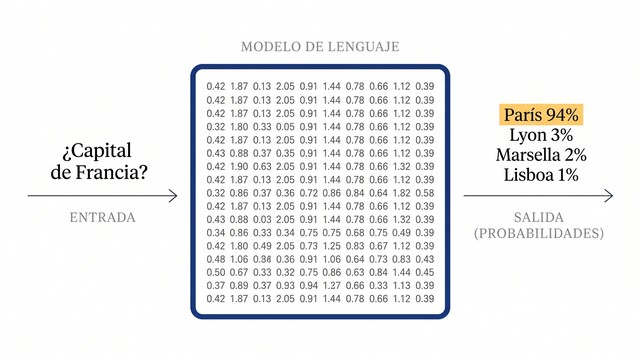
De ahí nace su límite más conocido: la alucinación. Una alucinación es una respuesta que suena coherente y segura pero es falsa: una cita inventada, un dato erróneo, una fuente que no existe3. No es un fallo puntual que se vaya a "arreglar" del todo, sino una consecuencia directa de cómo funciona un modelo que optimiza plausibilidad, no veracidad.
Hay otros límites que conviene tener presentes. Un LLM puede reproducir sesgos presentes en sus datos de entrenamiento1. Su conocimiento tiene una fecha de corte, salvo que se conecte a fuentes externas3. Y no razona sobre el mundo real: opera sobre texto.
Pero esto no va solo de precisión técnica. Va de criterio. La utilidad de un LLM no depende de que sea infalible, sino de que tú sepas cuándo confiar en él y cuándo verificar. Esa frontera, hoy, sigue siendo responsabilidad humana.
Si eres profesional, autónomo o gestionas una empresa pequeña, los LLM ya forman parte de tus herramientas aunque no los llames así: el corrector que reescribe un correo, el asistente que resume una reunión, el chatbot que atiende a tus clientes. Entender qué son cambia cómo los usas.
La primera implicación es práctica: trata cada respuesta como un borrador competente, no como una verdad verificada. Para redactar, ordenar ideas o traducir, un LLM ahorra horas. Para datos, cifras o citas, verifica siempre en la fuente original.
La segunda es de privacidad. Cuando usas un modelo propietario a través de su servicio, tu texto viaja a un servidor externo. Antes de pegar información sensible de clientes o de tu negocio, conviene saber qué hace la herramienta con esos datos. Aquí, un modelo de código abierto autoalojado puede ser la opción más prudente.
La tercera es de criterio profesional: el LLM acelera la ejecución, pero la decisión sigue siendo tuya. Quien aprende a formular mejores instrucciones y a optimizar su consumo —por ejemplo, cómo ahorrar tokens con Claude— saca mucho más partido que quien delega a ciegas.
LLM significa large language model, es decir, modelo de lenguaje de gran tamaño. Es un tipo de inteligencia artificial entrenada con grandes volúmenes de texto para comprender y generar lenguaje humano. El "gran tamaño" hace referencia a sus miles de millones de parámetros y al enorme corpus con el que se entrena.
No: un LLM es un tipo concreto de inteligencia artificial, no la IA en su conjunto. La inteligencia artificial es el campo general; un LLM es un modelo especializado en lenguaje dentro de ese campo. Existen muchos otros sistemas de IA que no son LLM, como los modelos de visión o de recomendación.
No exactamente: ChatGPT es una aplicación que utiliza un LLM por debajo. El LLM es el modelo (por ejemplo, GPT-5); ChatGPT es el producto que te permite conversar con él a través de una interfaz. Otras aplicaciones, como Claude o Gemini, usan sus propios modelos.
Porque un LLM optimiza qué texto es más probable, no qué texto es verdadero. Cuando no tiene información fiable, genera la continuación que parece plausible, lo que produce respuestas falsas pero convincentes, conocidas como alucinaciones. Por eso conviene verificar siempre los datos importantes.
No en el sentido humano: calcula probabilidades sobre secuencias de tokens. Reconoce patrones del lenguaje con enorme precisión, pero no tiene comprensión ni conciencia del significado. Su coherencia es resultado del modelado estadístico, no de un razonamiento consciente.
Los más usados en 2026 son GPT (OpenAI), Claude (Anthropic), Gemini (Google), Llama (Meta), DeepSeek y Mistral. Los tres primeros son propietarios y se usan a través de un servicio; los tres últimos tienen versiones de código abierto que pueden descargarse y ejecutarse de forma autoalojada.
